Monday, November 13: LLM Agents
 |
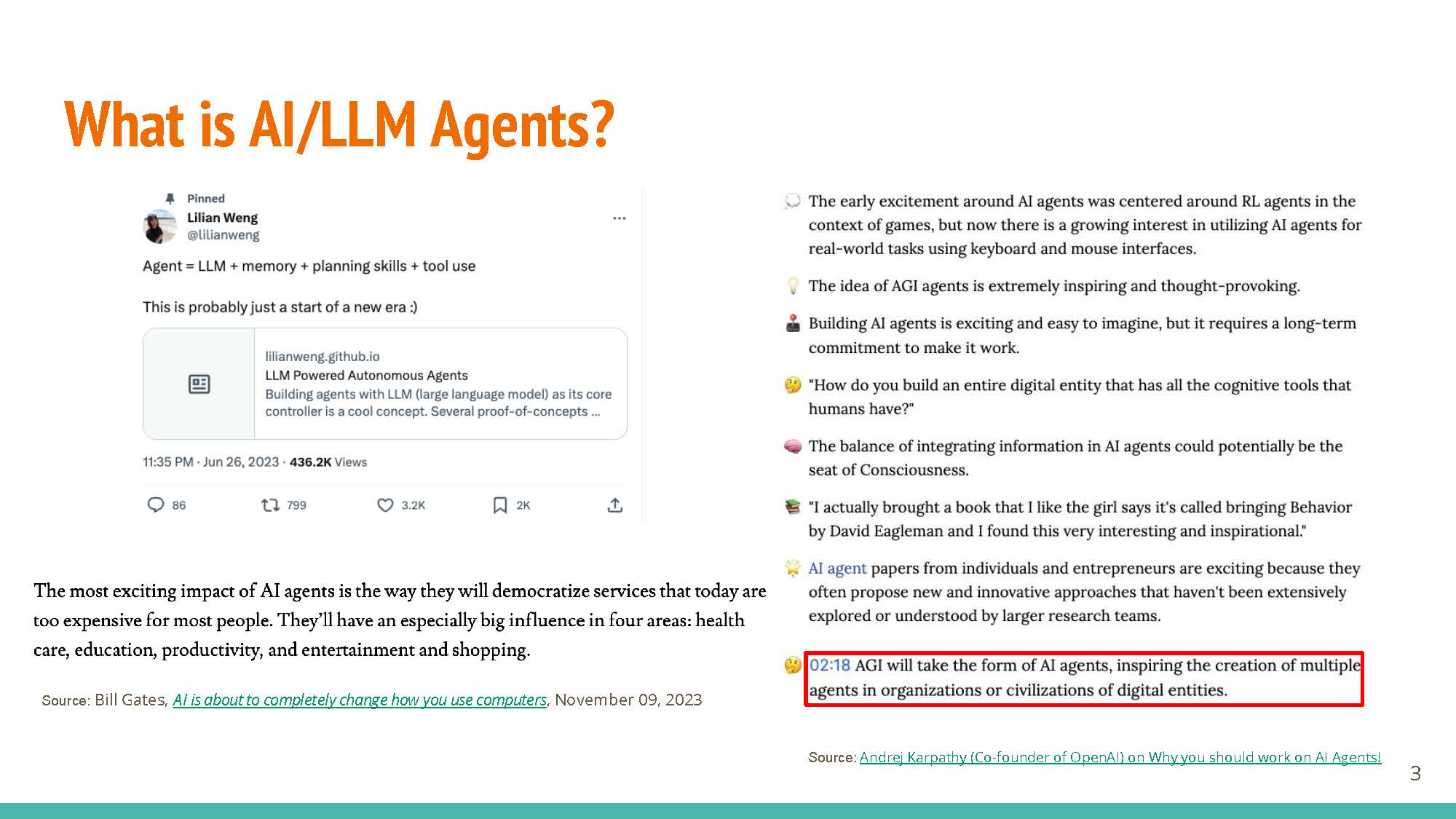
LLM agents are the “next big thing”, with the potential to directly impact important fields like healthcare and education. Essentially, they are LLM-based systems that have the ability to use external tools, such as Internet browsing access and calculators, to augment their abilities.
 |
Toolformer
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv 2023. PDF
LLMs have limitations that can potentially be addressed with these “tools”:
 |
- Outdated information: LLMs cannot access up-to-date information without access to external sources. Giving them the ability to access realtime information (via Internet queries) would lead to better responses, such as “who is the President of USA today?”
- Hallucination: External knowledge sources can help ground generation in facts and work to supplement the model’s knowledge, reducing the possibility of hallucinating.
- Lack of mathematical skills: Access to a calculator can help model generate correct responses and computations involving math. Using zero-shot learning can help reduce hallucination, but providing access to a calculator (assuming it is used correctly) can guarantee correct responses.
Other limitations include limited multi-language usability, having no concept of “time”, etc.
 |
Key Contributions
 |
The main idea is to develop a system that has the ability to use external tools (translation, calendar, search engine, etc.). The key lies in knowing when to use a tool, which tool to use, and how to use it. Training is self-supervised, unlike other capability-enhancing techniques like RLHF.
Data Collection
 |
Key step: generating candidate API calls via in-context learning. The method starts with examples generated by humans, e.g. in-context examples for “Coca-Cola”, etc.
 |
$k$ positions are sampled at random from the text to serve as “candidates” for adding <API> tags.
 |
Tokens up to the position with an “
 |
An additional weighted loss term is introduced, corresponding to the utility of information added after using candidate API calls. This loss term is meant to provide feedback for which API calls were useful for some given context.
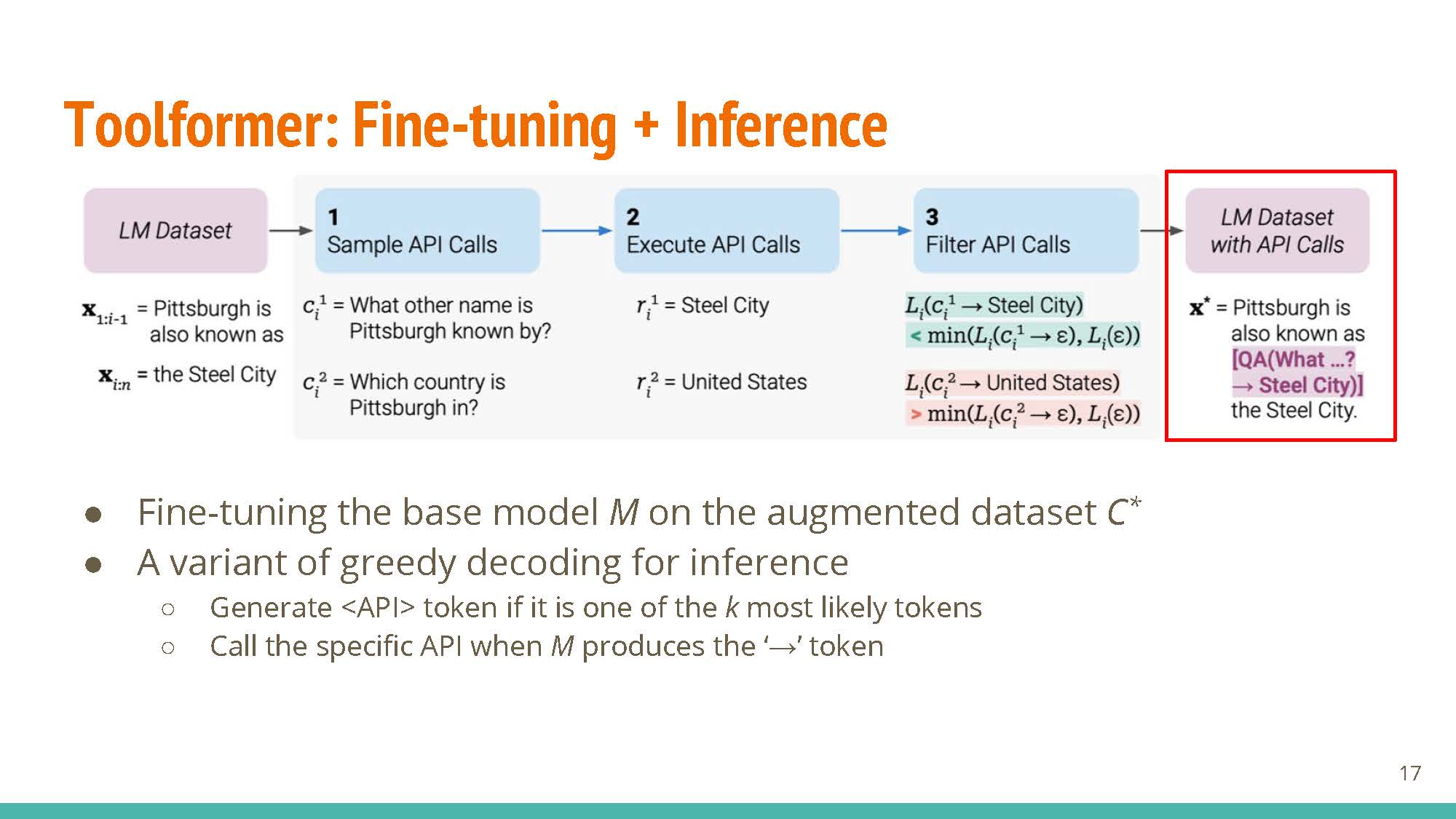 |
Given the loss term and general strategy for inserting <API> tokens, the model is fine-tuned with the augmented dataset. At prediction time, the model uses a variant of greedy decoding, making API calls if the <API> tag is in the top-k predictions at any token position.
Professor Evans talked about how the method could benefit from having some “feedback” from the API’s quality of response, and not having an implicit bias in the design that considers API calls as “costly”.
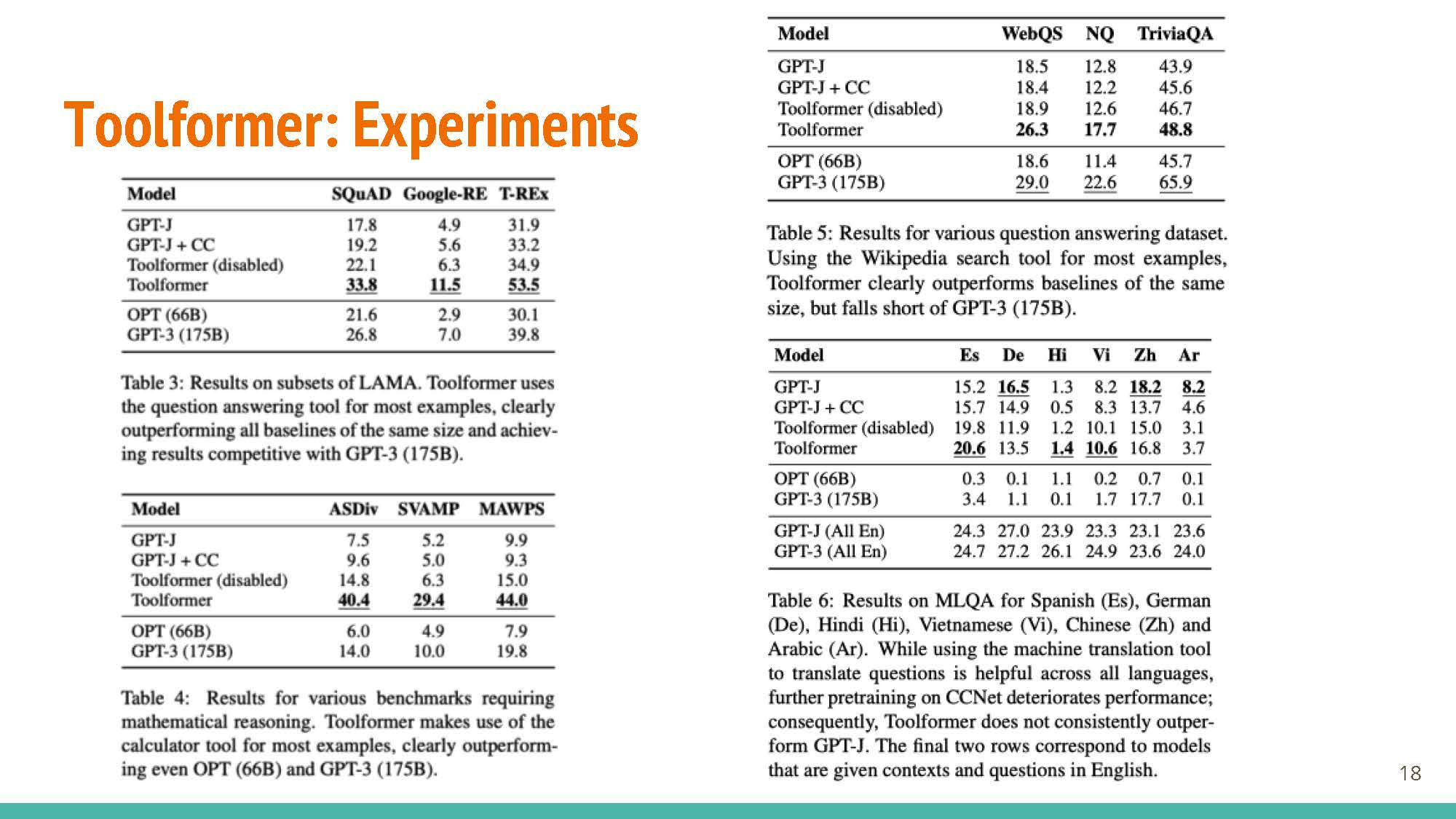 |
Interestingly, performance for some cases (ASDiv, Table 4) is better for the version with disabled API calls (so no agent-like behavior) than the variant equipped with API-returned information.
Scaling-law Experiments
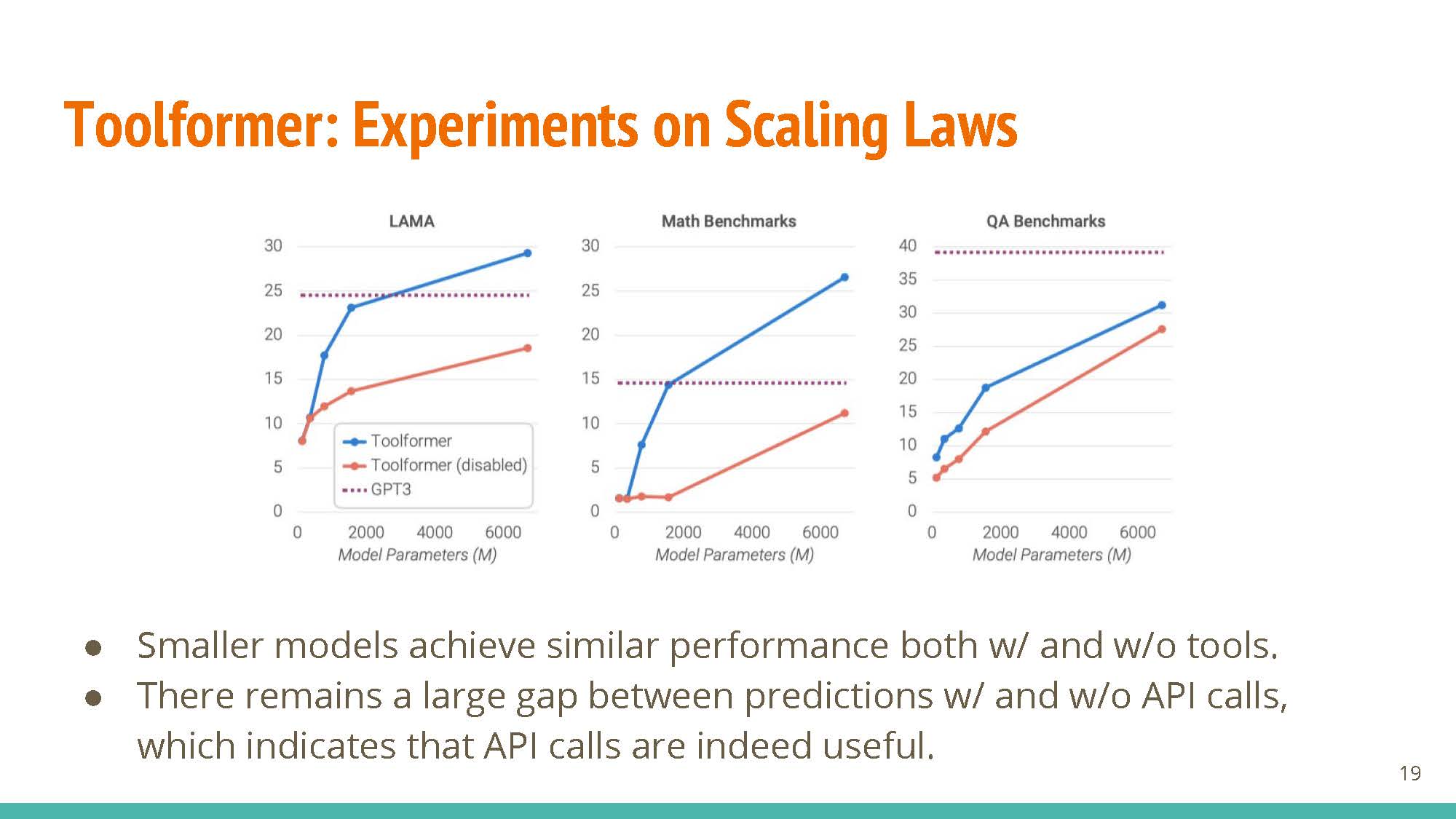 |
- For small model sizes, performance does not change much with the inclusion of external knowledge.
- The utility of API calls is clearer for larger models, where performance drops significantly when API calls are disabled.
In terms of limitations, these tools cannot be used “in chain” (an in iterative-refinement approach, where multiple API calls are made) and require sampling a lot of data.
ReAct
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR, 2023. PDF
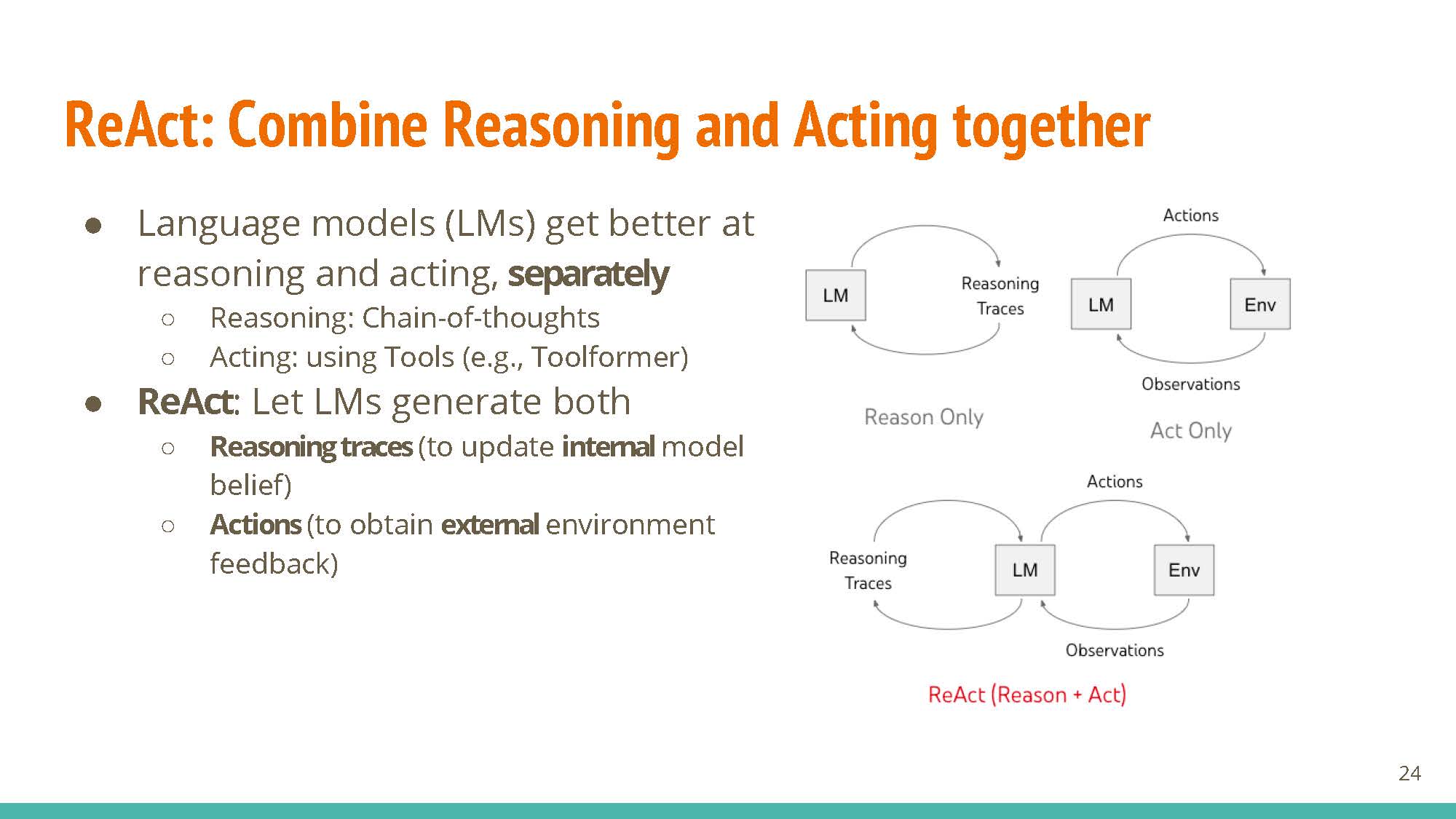 |
Research on reasoning and acting has been detached from each other. This work allows LLMs to generate both reasoning traces and actions.
 |
Learning based on fine-tuning and prompting (ReACT prompting strategy, uses reasoning & action steps together as prompt). The new few slides (below) talk about different parts of ReACT via secific examples, showing how just actions or reasoning in isolation are not sufficient for good agents.
 |
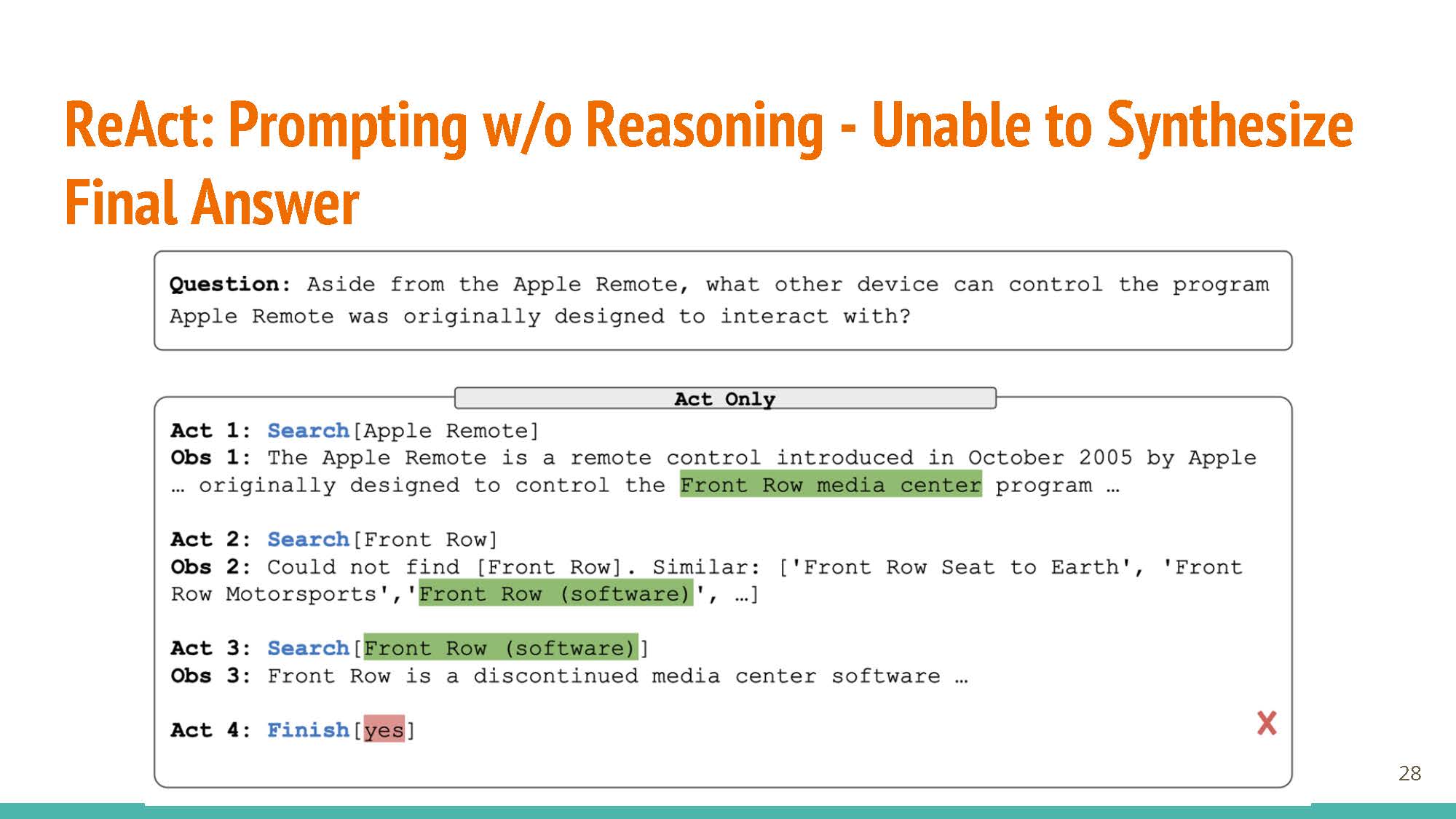 |
Only when these two are combined together do we get powerful LLM agents:
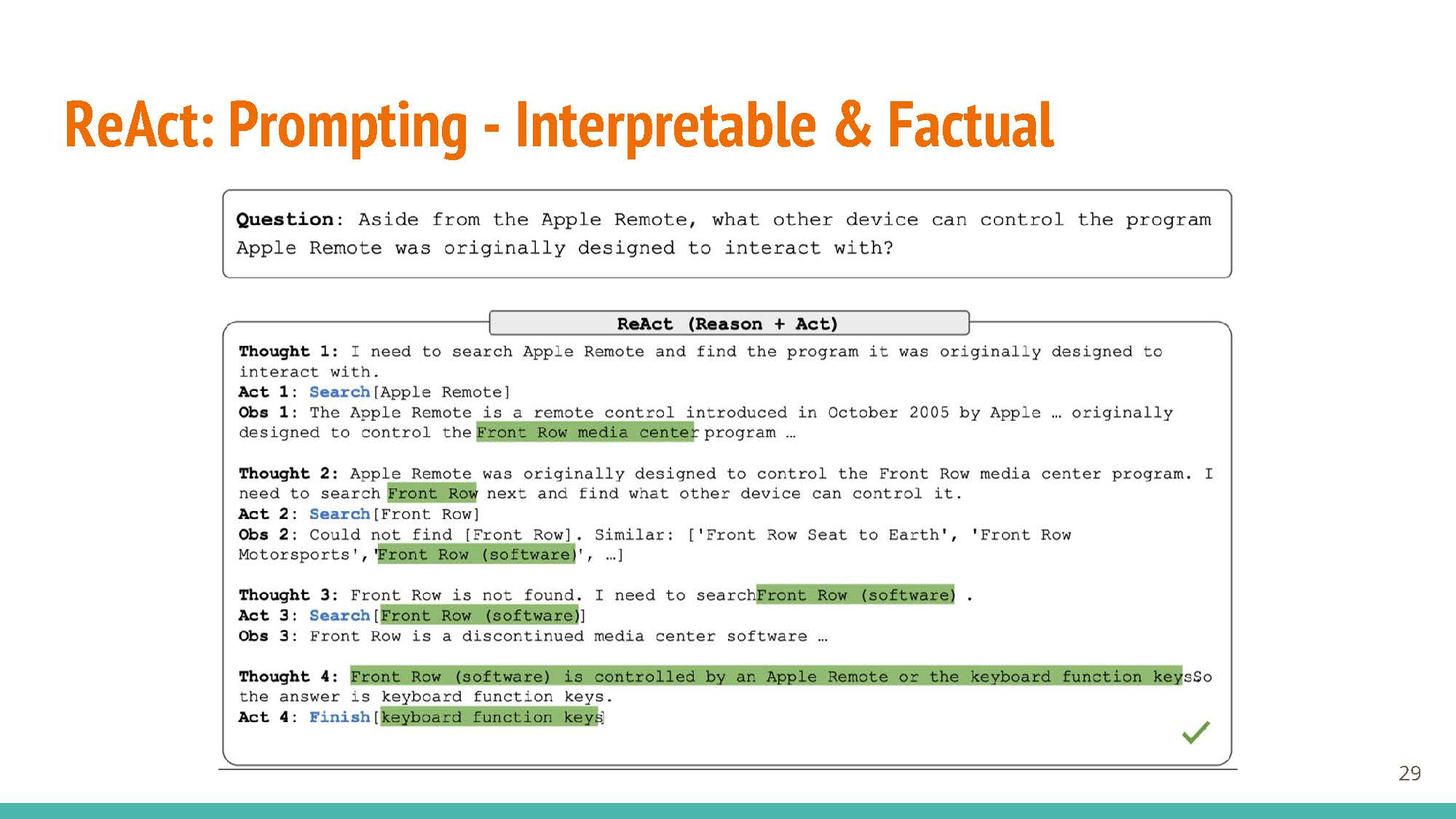 |
 |
Reasoning and acting together create an augmented action space, which is key to unlocking these models’ capabilities.
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen. A Survey on Large Language Model based Autonomous Agents. arXiv, 2023. PDF.
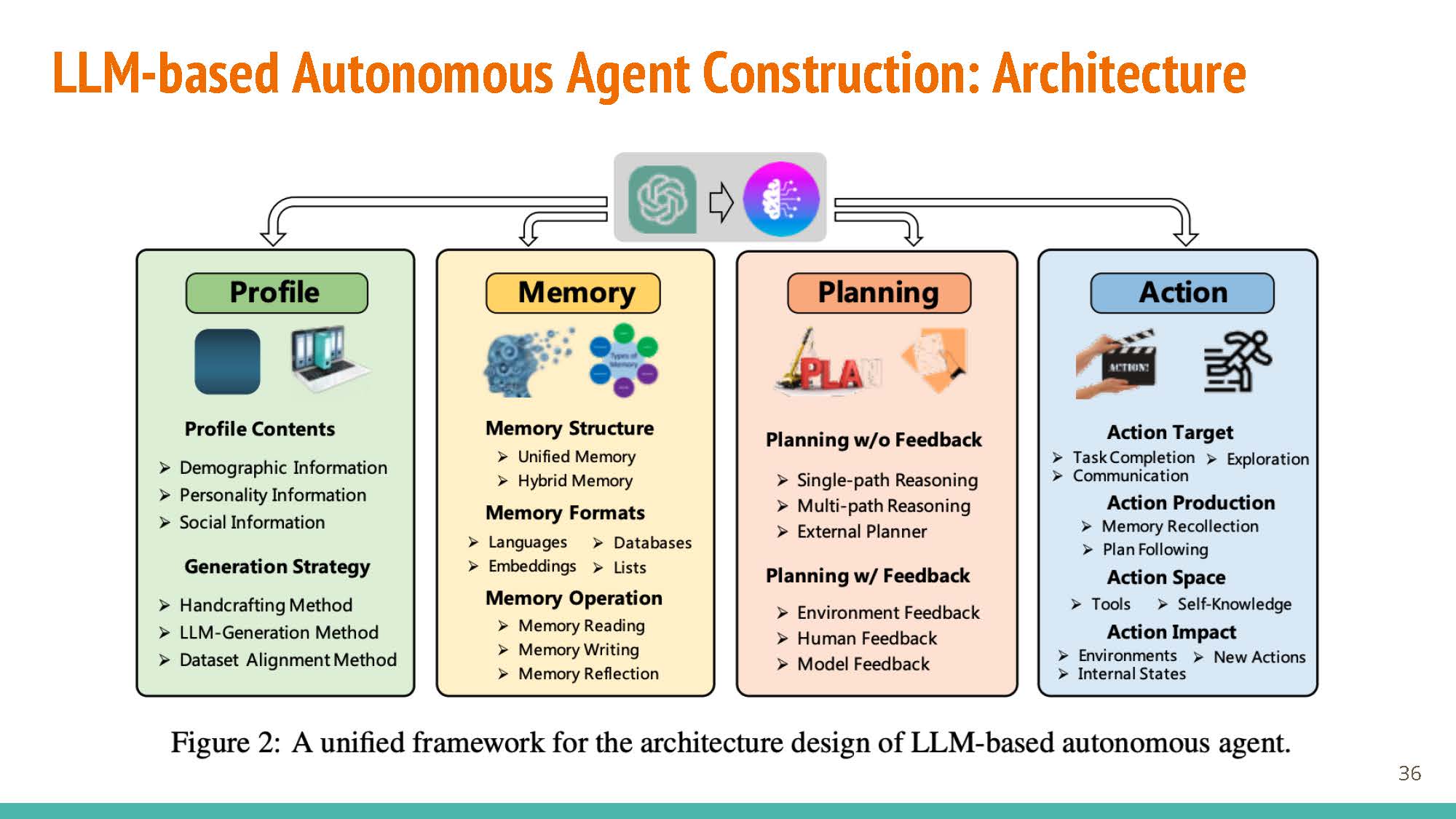 |
The survey breaks down the agent construction pipeline into four components/modules: profiling, memory, planning, and action.
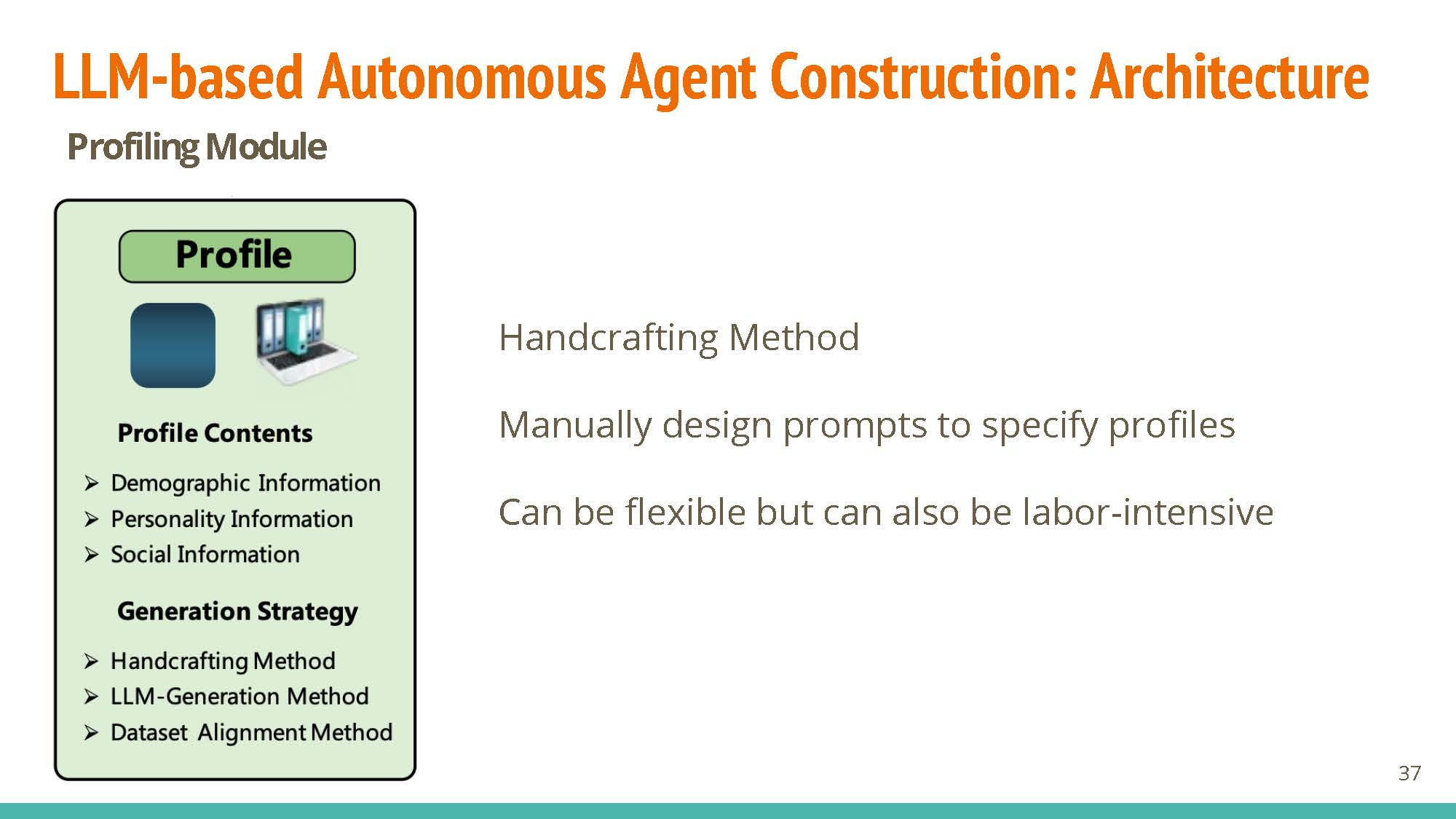
Profiling
 |
 |
 |
- Handcrafted: captures the role of agent properly and allows for flexibility, but labor-intensive.
- Using LLMs: starts with profile generation rules (can specify via few-shot examples), controllable seeding for profiles.
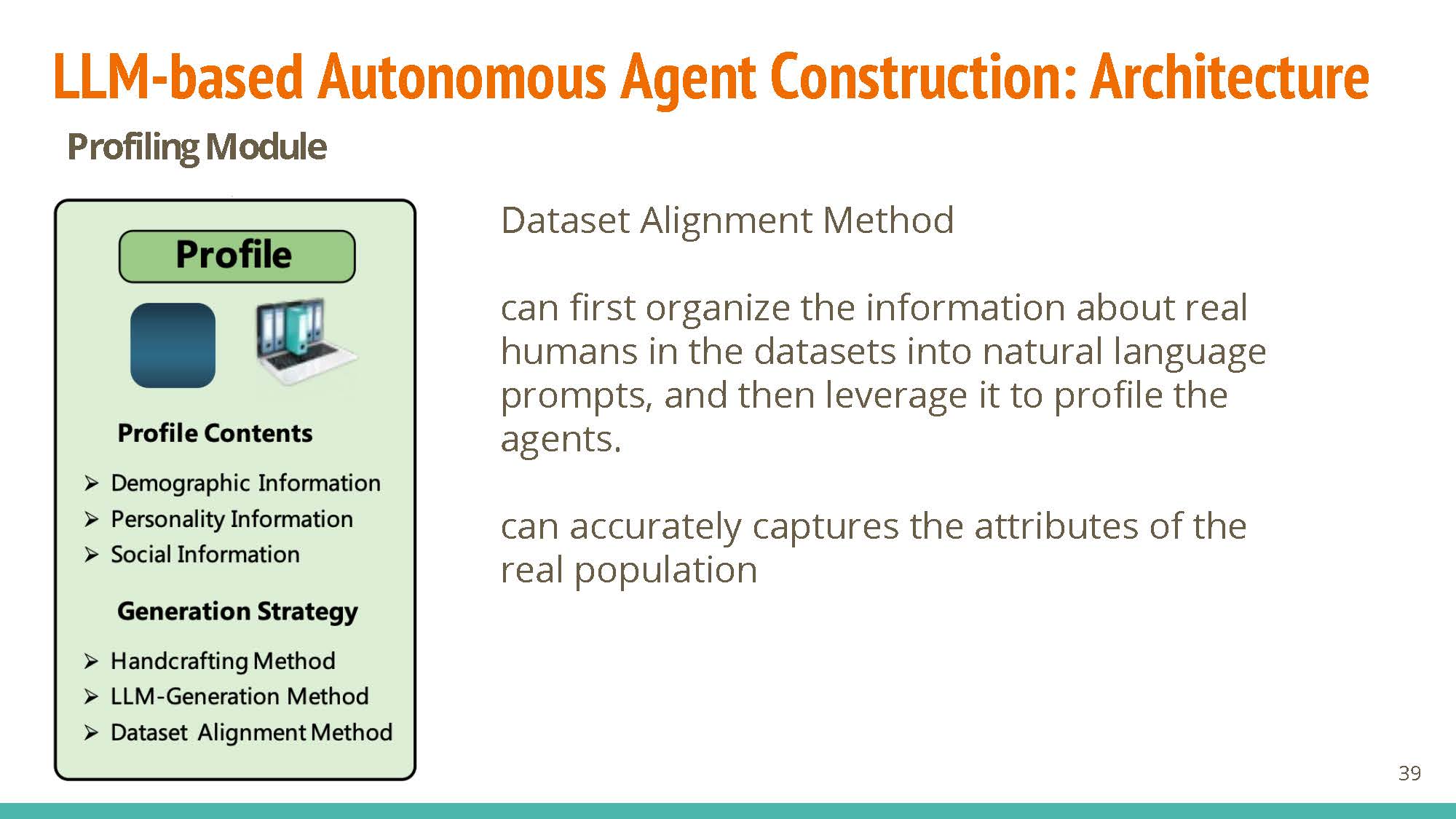
- Dataset Alignment Method: foundation of agent design, and has significant influence on the following 3 modules.
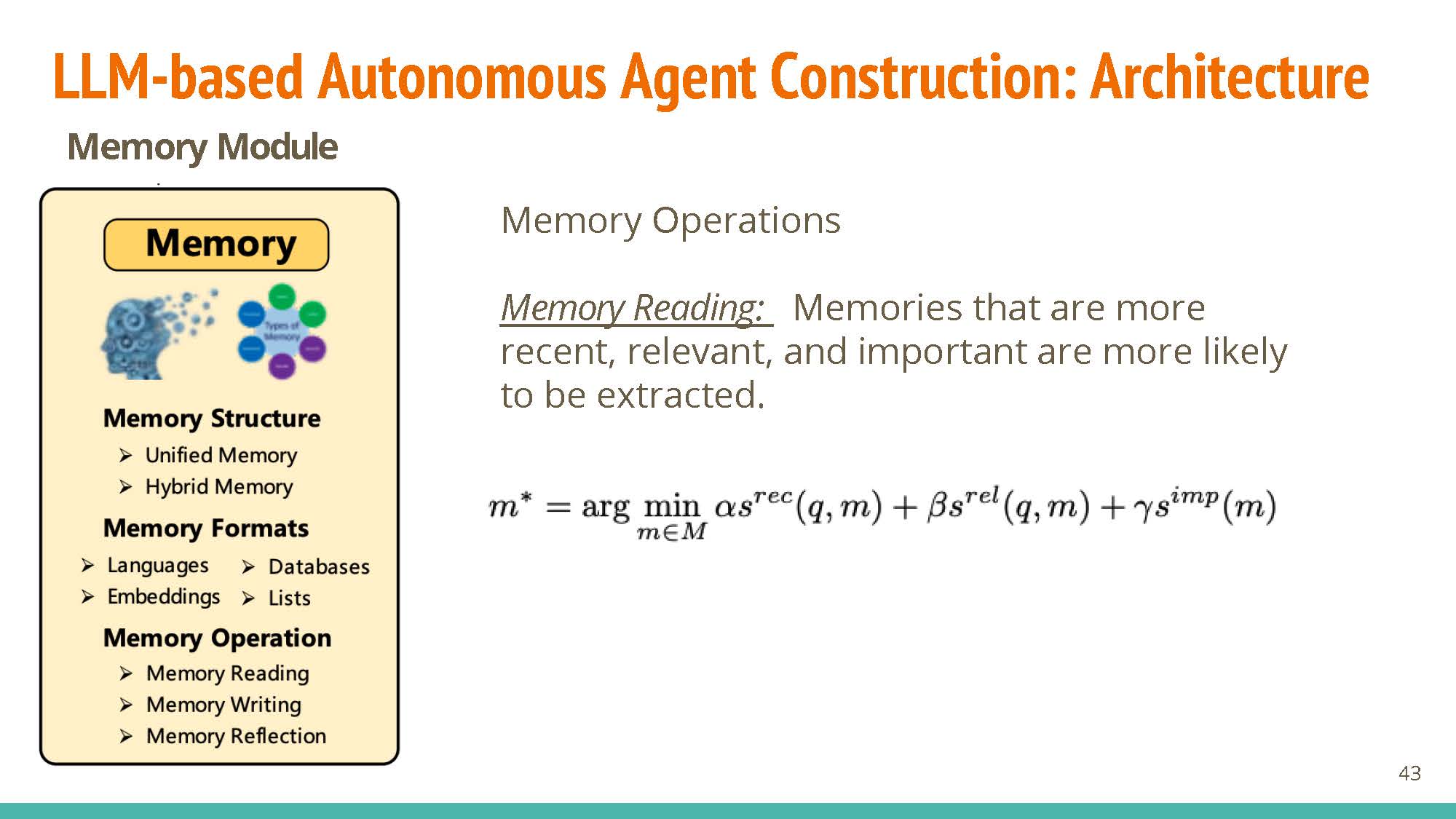
Memory
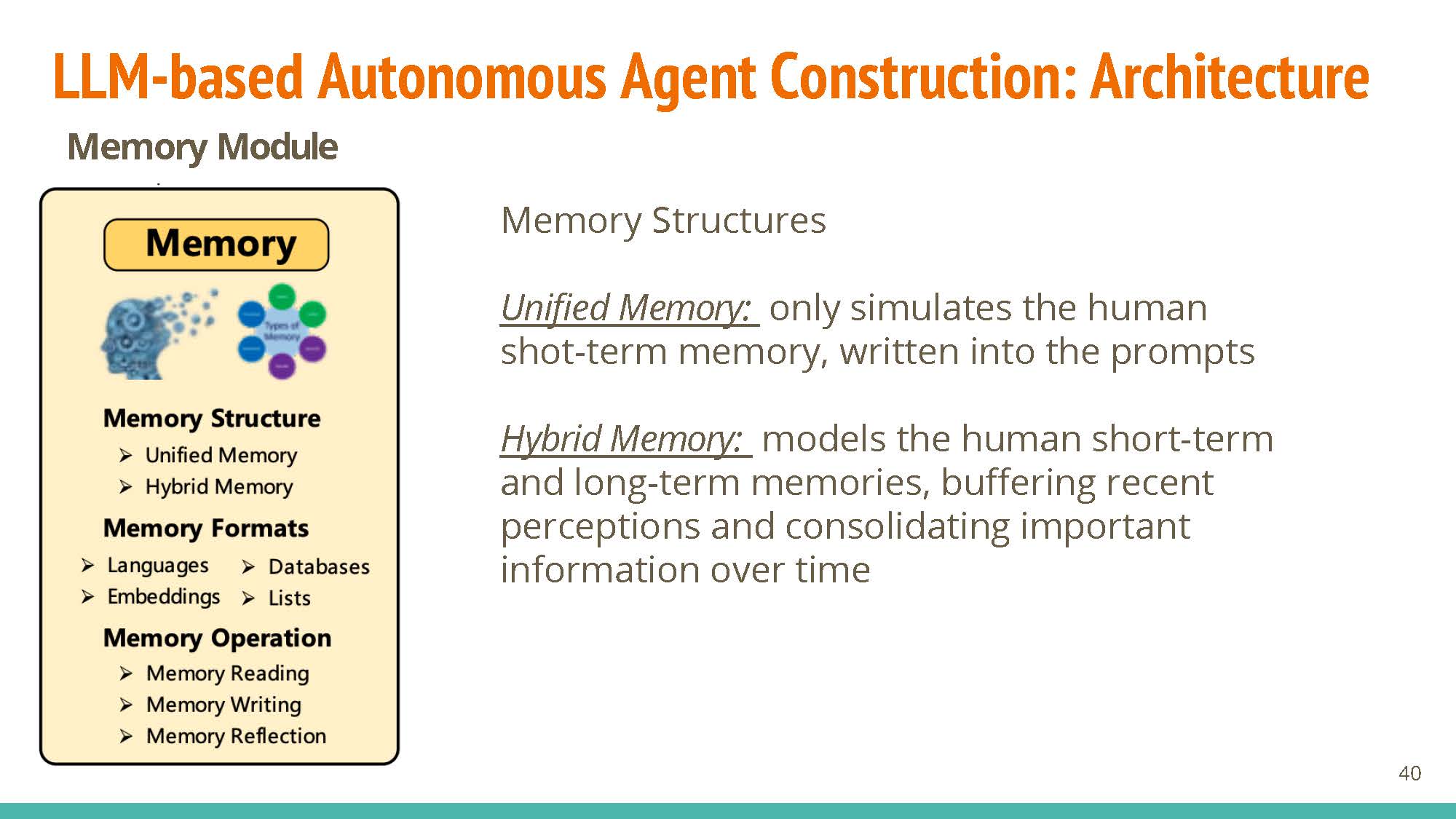 |
Structures: Unified memory is short-term and simulates our “working memory” (added via context), while hybrid combined short-term and long-term memory tries to model human recollection better.
 |
 |
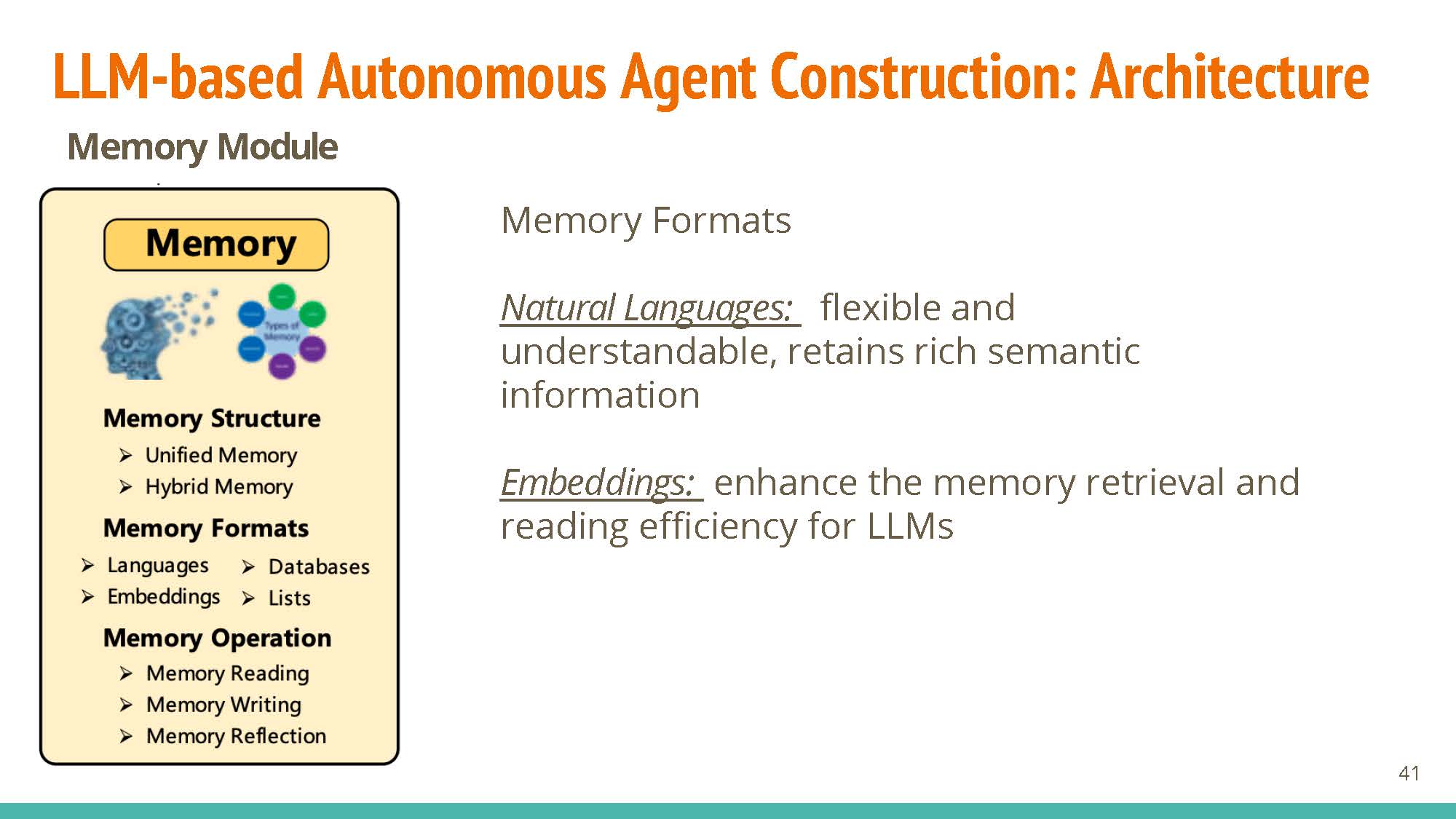
Formats: natural language is interpretable and flexible. Embeddings compromise on this flexibility, with the added benefit of being very efficient. Databases allow efficient manipulation of “memories”, and structured lists can also be used.
 |
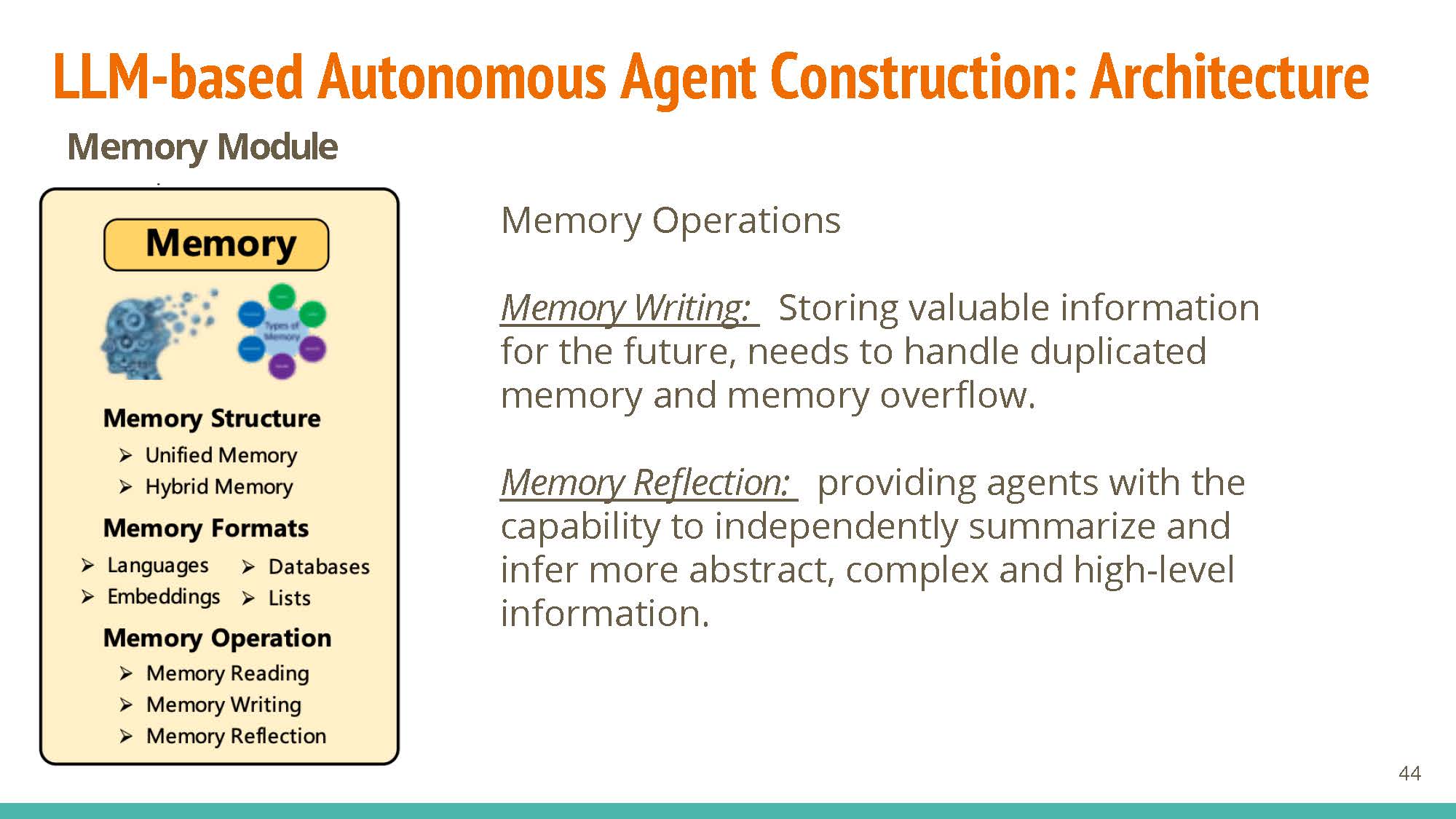 |
Operations: Memory reading allows for weighted retrieval of information, with operations for reading (memory reflection) and updating (memory writing) information.
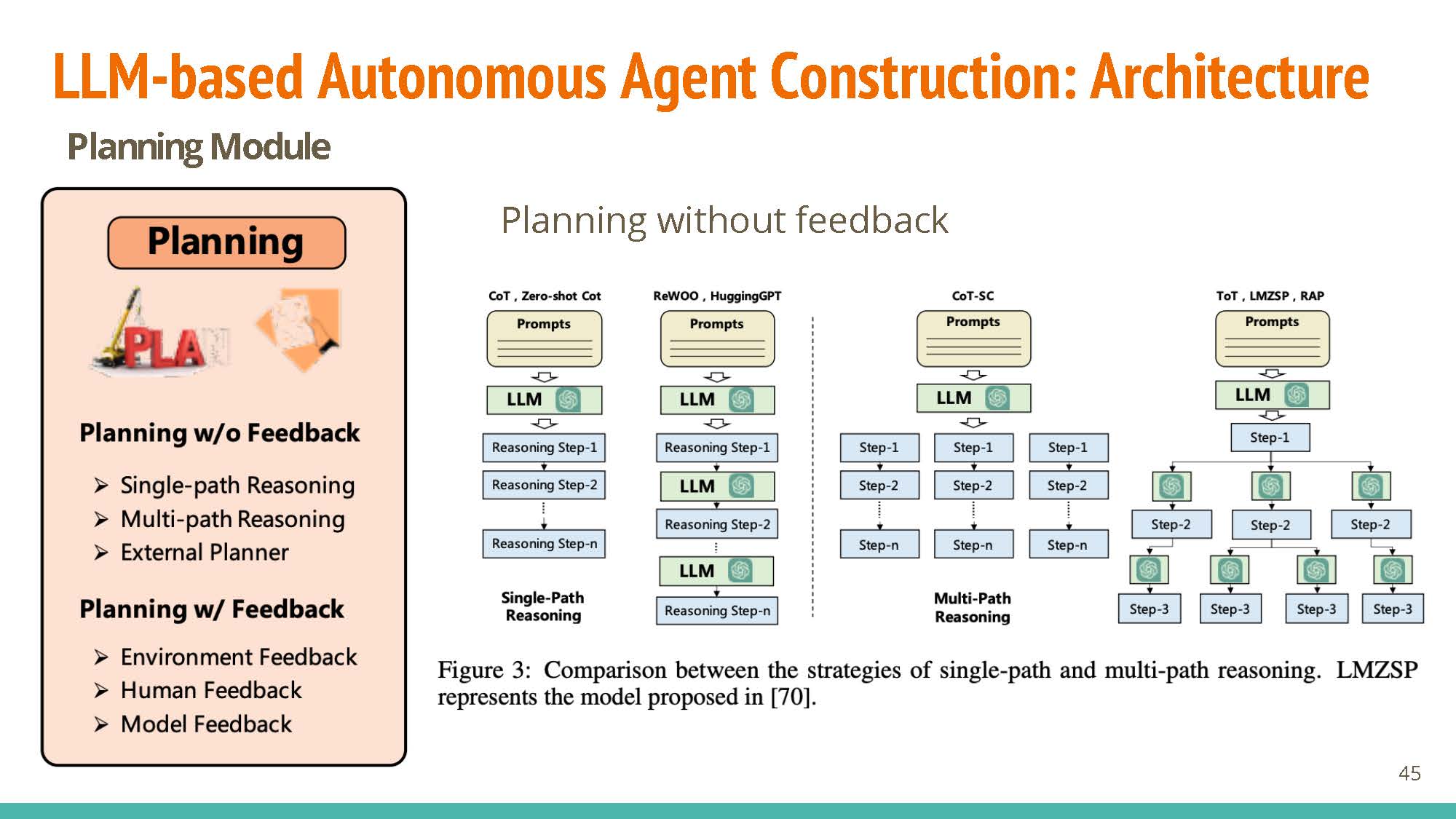
Planning
 |
 |
Without feedback, planning may proceed via single reasoning (dependent, connected steps), multi-path reasoning (tree-like structure, kind-of approximates human thinking?), or using external planners (using domain-specific planners).
Similarly, planning with feedback may rely on information from humans (e.g. RLHF), environmental feedback (e.g. RL for game simulation), or model feedback (using other pre-trained models).
Action
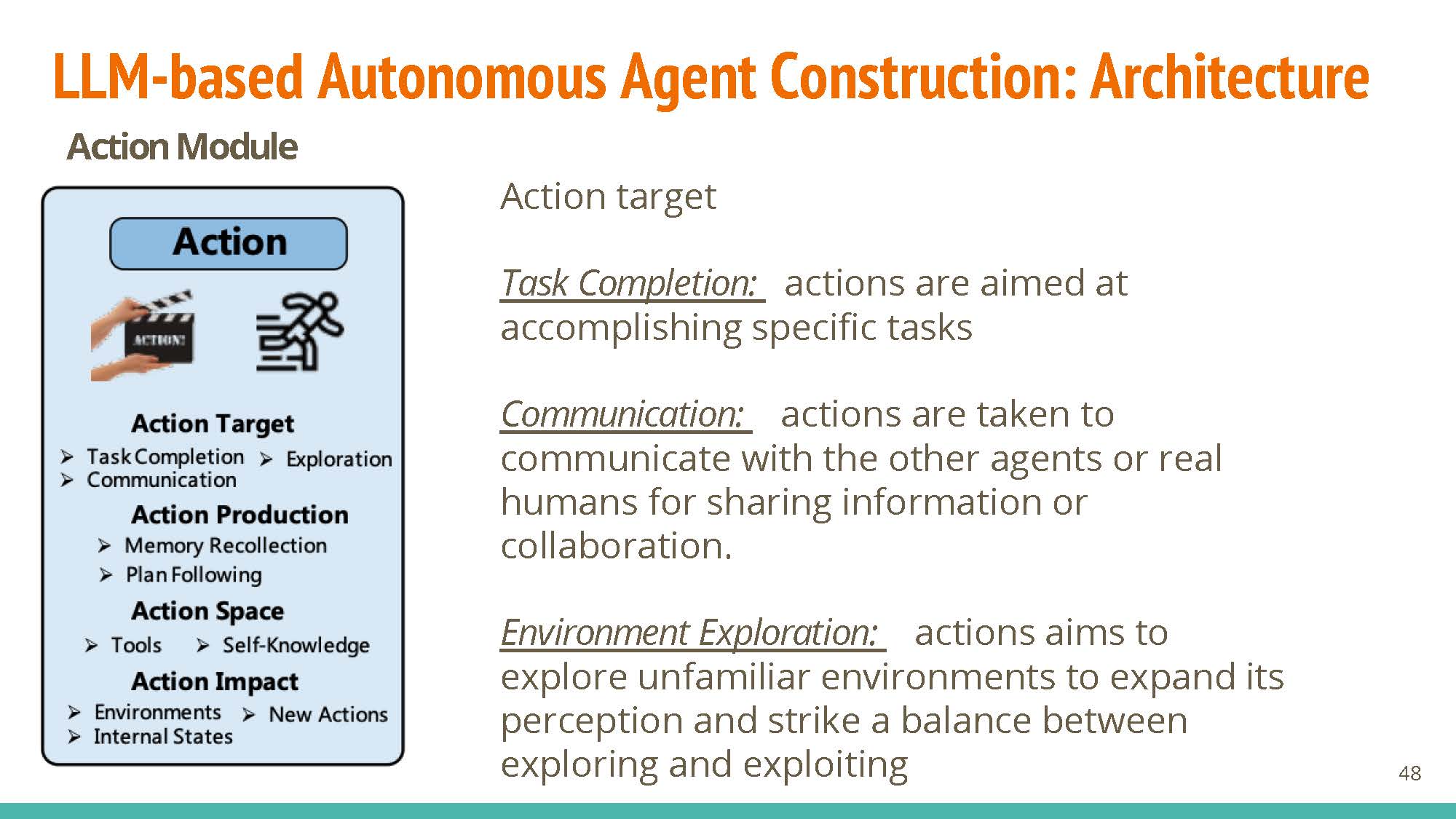 |
- Agents can have different targets: task completion, communication (communicate with other agents/humans), or exploration (explore vs. exploit tradeoff).
- These actions may be produced via memory recollection (using short-term or hybrid memory), or following generated plans.
- Their exploration space may include API calls, or internal knowledge.
 |
Impact: These agents can directly change the environment (e.g. starting a calculator service), their own states (e.g. recollection), or trigger actions in other agents (e.g. a chatbot agent calling a legal-information agent)
Subbarao Kambhampati. Can LLMs Really Reason and Plan?. Communications of the ACM Blogpost, 2023.
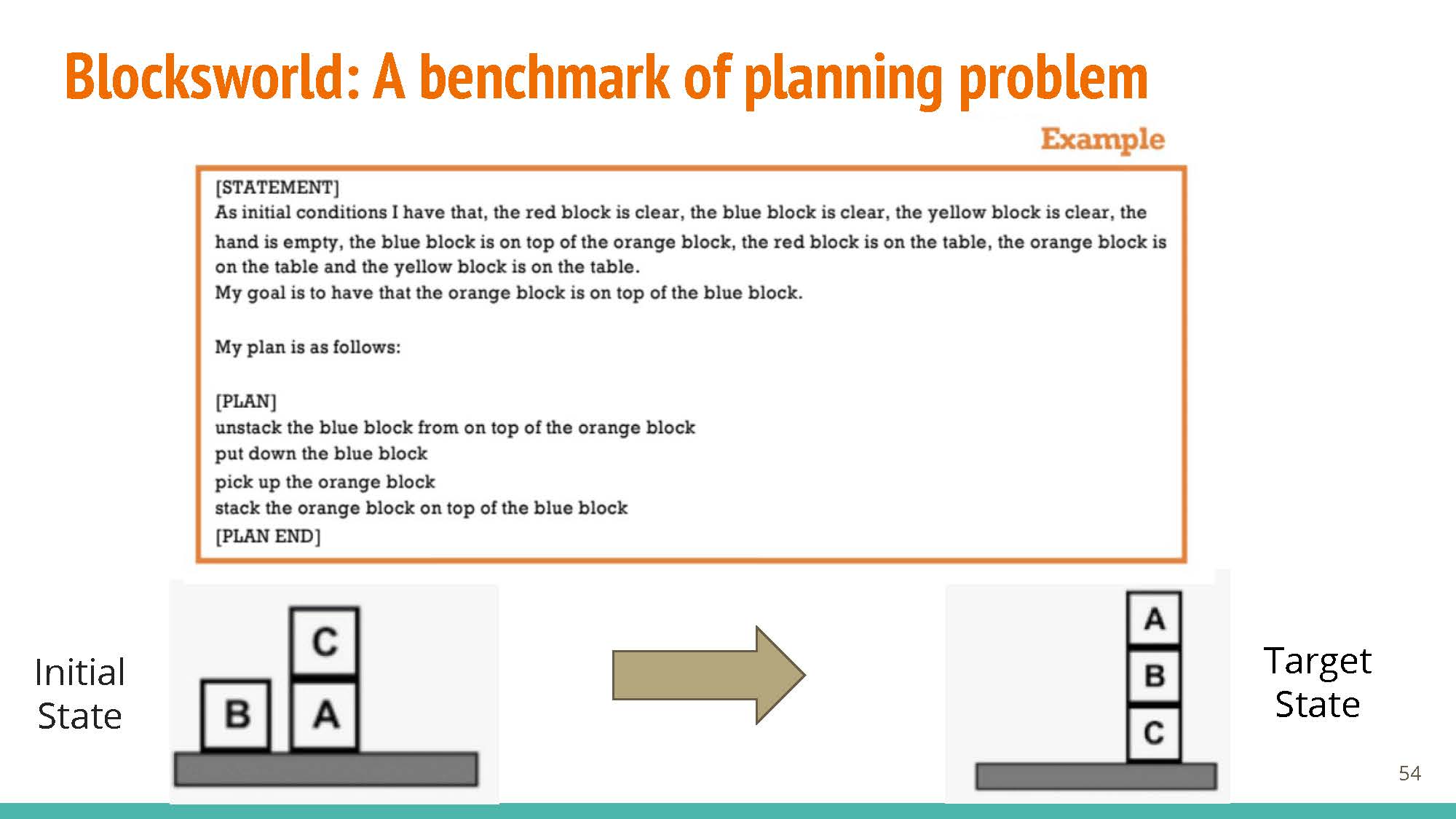 |
The blogpost discussions use Blocksworld as a benchmark. Blocksworld defines rules, goals, and allowed actions etc. via natural language, expecting a set of instructions in response.
 |
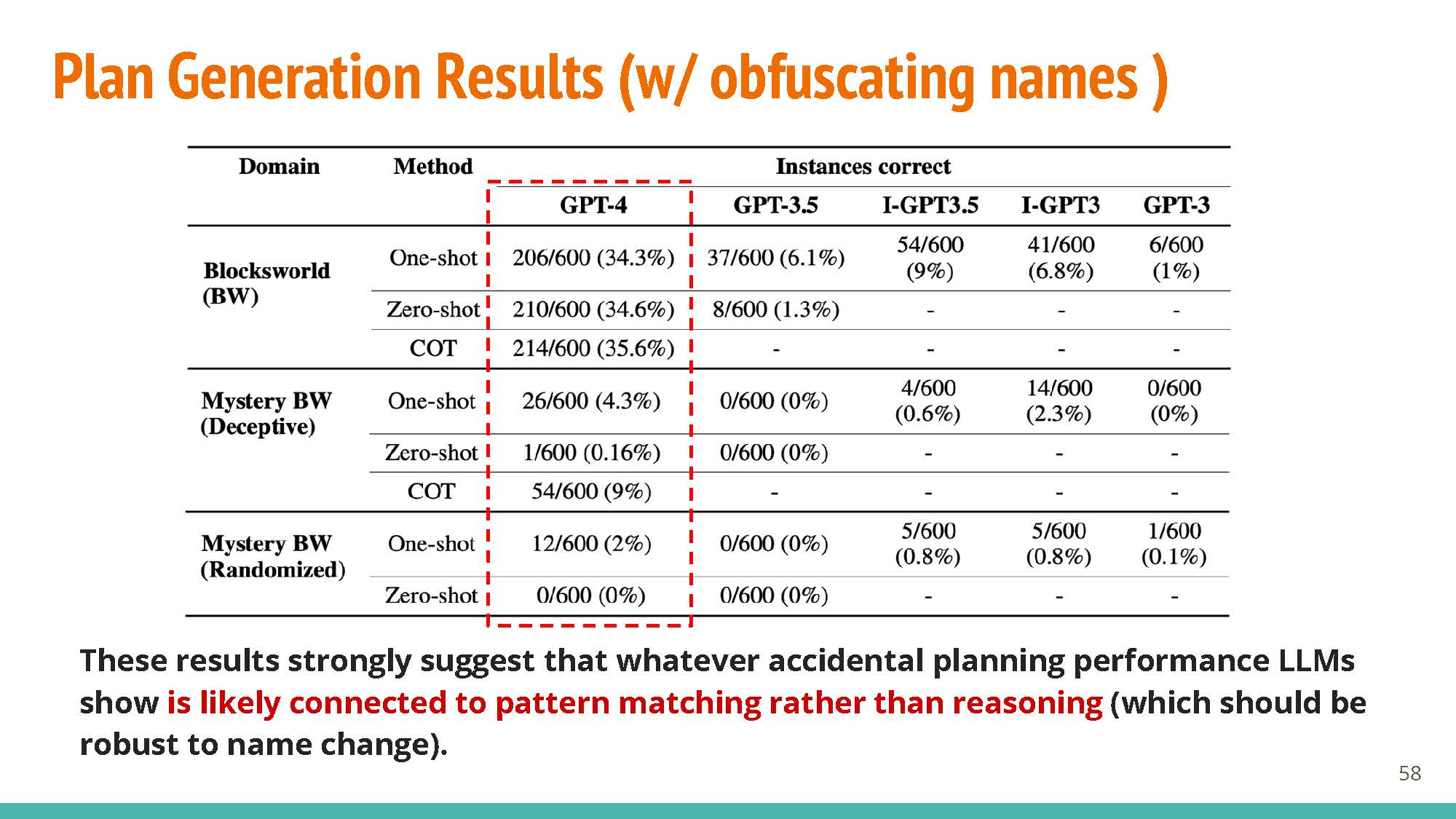 |
Performance seems pretty good with GPT-4 (Left, ~35%) but when names are obfuscated (Right), plan generation results drop to 0-2%.
Professor Evans talked about how the benchmarks are not a comparison with human performance, which would also understandably go down when names are obfuscated. It is thus unclear whether these drops in performance are expected (given that humans are bad at the modified task as well), or a result of the model not really “knowing” how to solve the given task. An alternate explanation for these results, would just be that the model has a hard time identifying entities that are labeled with non-sensical, multi-token strings that don’t revaal them to be blocks. That said, there is tons of data about Blocksworld in the training data, so a difficult domain to test what the model is really learning (if anything).
In-class Discussion
 |
- What are your thoughts on LLM reasonig/planning? We talked how in psychology, reasoning is divided into 3 domains (knowledge acquisition, reasoning, decision making). Even for the literature in this field, it is unclear how these three domains interact with each other, and thus even more complicated for LLMs.
- How should we proceed with this line of research? We acknowledged how it is difficult to define “planning” for both humans, and even more so for LLMs. Professor Evans mentioned that for this line of work to advance, we need to come up with a good benchmark (but this is very labor-intensive). Students recalled work on performing activities in Minecraft as a useful benchmark for planning and agents. The “granularity” of planning is much more nuanced - humans can infer steps in between (or use domain knowledge), but harder if talking about agents or “just LLMs”. At the same time, we do not have a good answer for “should we expect our model to behave more like a hard-coded program or like a human (performance changes due to new factors, ex. Semantic changes, etc)?”
Wednesday, November 15: Applications of LLM Agents
 |
The experimental setup comprises two restaurants, serving as competitive agents, and fourteen customers, acting as judge agents. To confine the action space of the Large Language Model (LLM), a management system is employed. This system functions as a question provider, formulating precise inquiries for the LLM to ensure that its output remains within the defined action space. The customers exercise their judgment when evaluating offers from both restaurants, ultimately selecting based on their individual constraints and requirements.
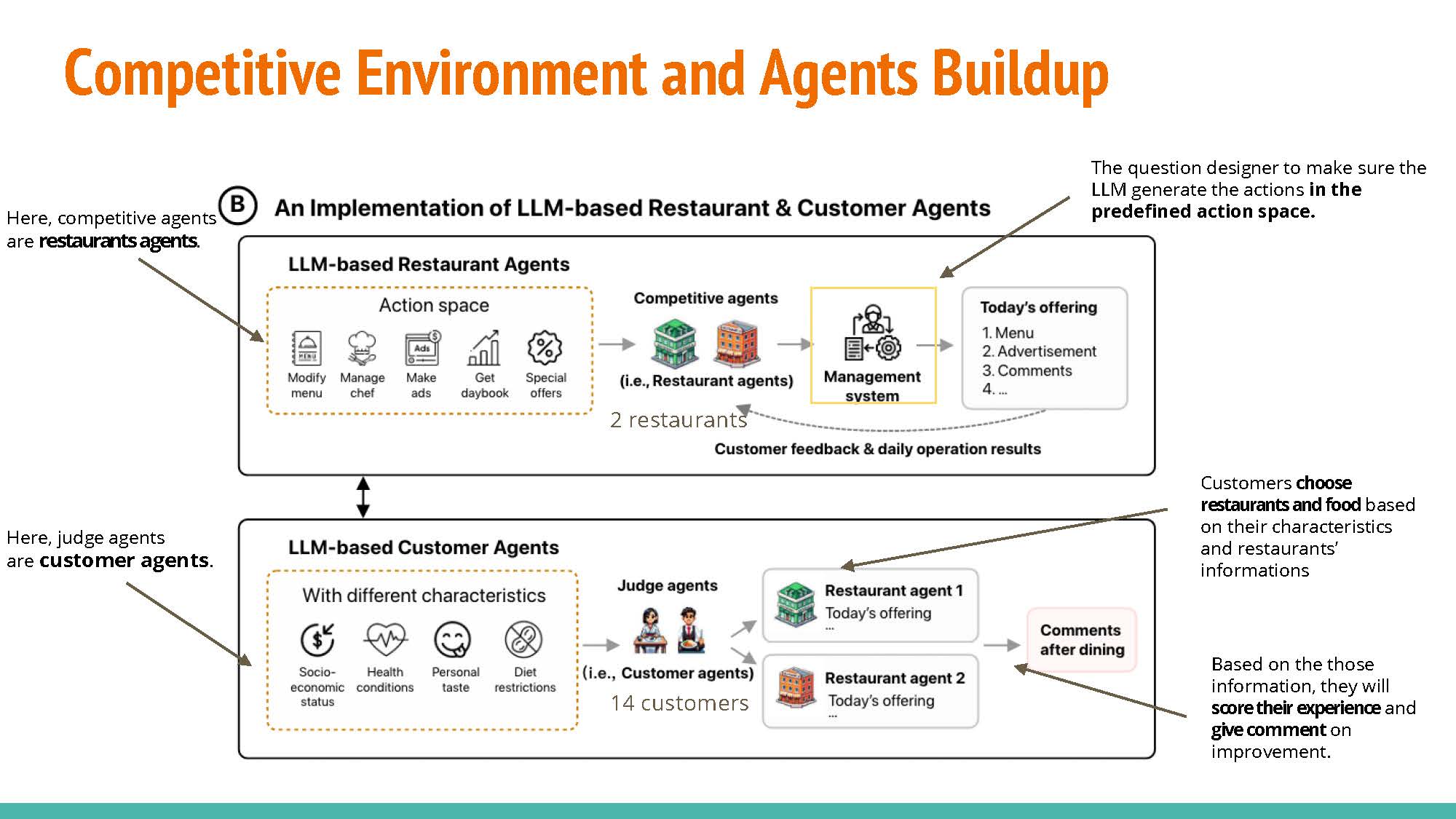 |
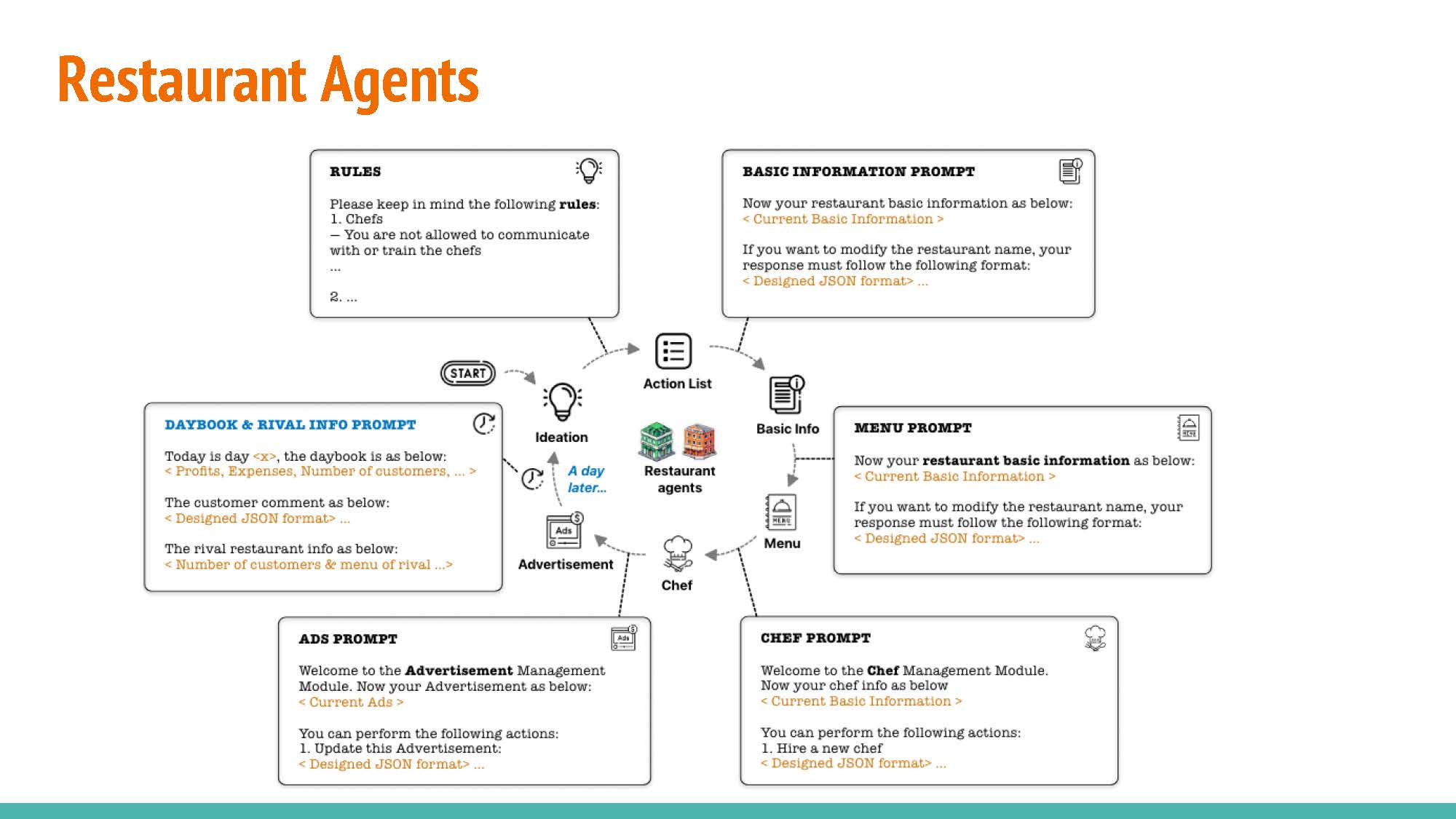 |
 |
Data inputs: Daybook provides data regarding the previous day’s patronage, menu evaluation, and related insights. Likewise, Rival offers comparable information concerning the competitor’s restaurant, encompassing visitor statistics and menu alterations. Customer feedback is used to make decisions about the next day.
 |
Discussion Notes:
- LLM scores can act as a baseline, but there is always a possibility of bias. For instance, changing the order of options presented to the model may sometimes result in a different score being outputted.
- Designing a model based solely off of customer/restaurant data fails to capture other experiences of dining (i.e. customer service, environment/ambience, etc.) and thus indicates the simulation’s low fidelity. Capturing decision-making factors in customers is especially difficult, as they are difficult to define and quantify. The current simulation does not account for customers’ risk-aversion for trying new dishes, and it also does not consider the influence of star ratings or reviews on customers’ decisions to choose between the two restaurants. There may also be issues with prompt-based tasks, such as over-generalization.
- Utilizing simulations has the potential for real-world social trends and phenomena to be reproduced without requiring a large number of real people or complex variables; it is not necessary to recreate an entire town in order to gain insights into real-world trends.
 |
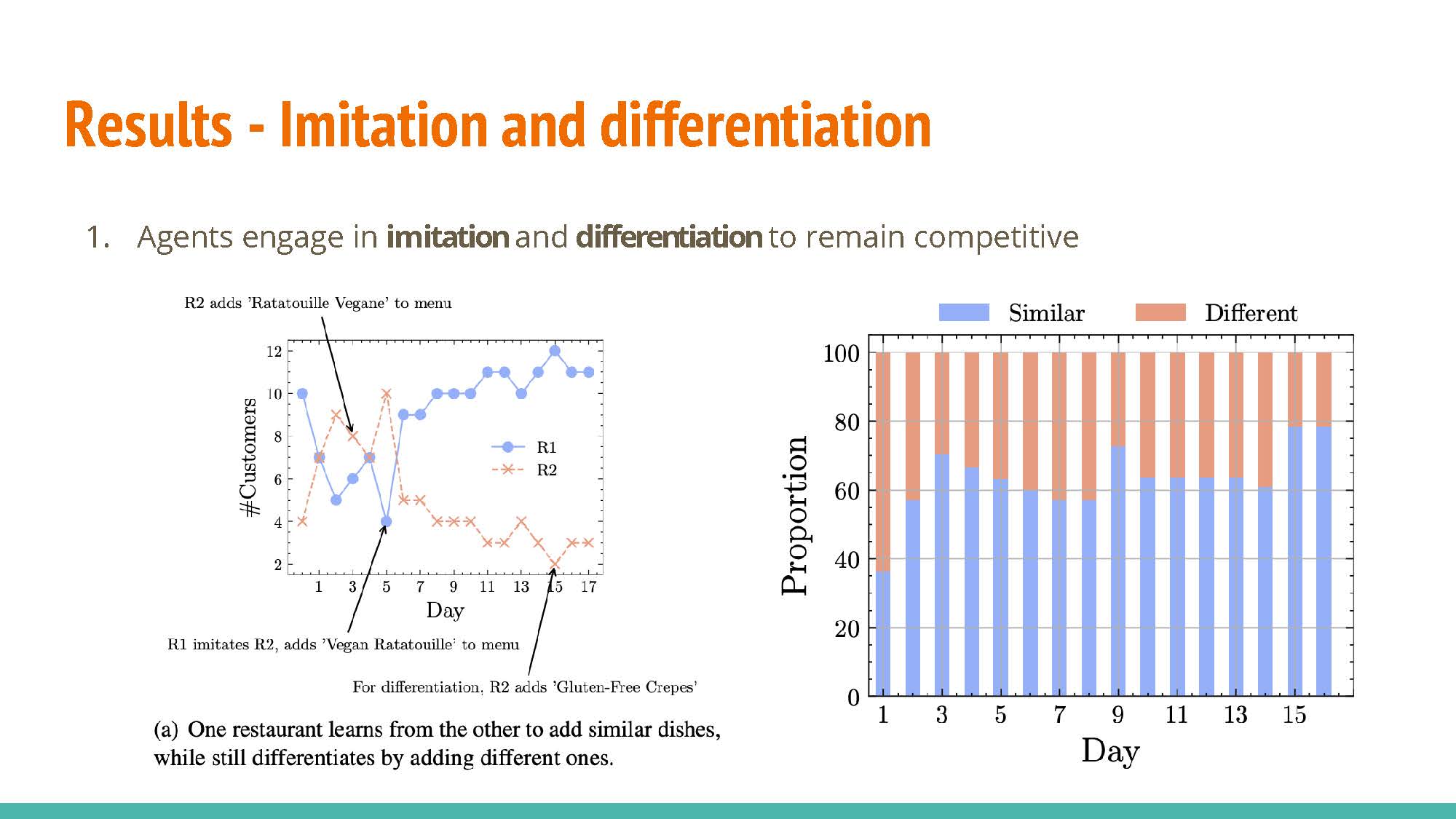 |
Agents are able to learn from each other while maintaining differentiation. This is visible in two ways:
- Agents imitate observed strategies that provide a high reward. For example, a restaurant may copy the popular dishes of another restaurant to compete for their clinetele.
- Conversely, differentiation is used to attract patrons that the competing agents don’t specifically cater to; one restaurant may provide inexpensive food for customers on a budget while another provides fine-dining options.
 |
The agents are shown to adapt to various customer needs in an effort to retain or attract further patronage.
 |
A number of sociological and economic princples were demonstrated in the experiment.
 |
- Is competition among agents the best mechanism to take advantage of their capabilities? What are the limitations of this approach?
- What other interactions are feasible?
- What are the benefits and risks and/or pros and cons of these interactions as compared to competition among agents?
Collaborative Approach Limitations: One potential drawback of adopting a collaborative approach is the propensity for bias in a single agent to propagate through multiple agents, thus amplifying its impact.
Employing Negotiation-Based Tasks and Games: In the context of collaborative endeavors, employing negotiation-based tasks and games is a valuable strategy. These involve the participation of diverse agents, such as a managerial figure, a chef, and a waiter, each representing distinct stakeholders. The amalgamation of their inputs contributes to a holistic decision-making process.
The Feasibility of Restaurant Collaboration: We explored the possibility of restaurants engaging in collaborative efforts, including the exchange of information regarding signature dishes, the potential collusion to elevate pricing structures collectively, and the coordination of operational hours. However, it is essential to consider potential drawbacks, particularly the willingness of competitors to engage in such cooperative ventures.
- Limitations of having collaborative approach: bias in one agent might cascade into bias in multiple agents.
- Discussed negotiation-based tasks and negotiation games to collaborate with each other. For instance, one could have an ensemble of different agents (i.e. manager agent makes final decision, chef has a say, waiter has a say, etc.) Each agent represents different stakeholder
- Discussed how restaurants could collaborate together, e.g. communicate signature dishes, collude to raise prices of everything, coordinate times they are open. Noted potential downsides, including willingess to collaborate and power dynamics between agents.
 |
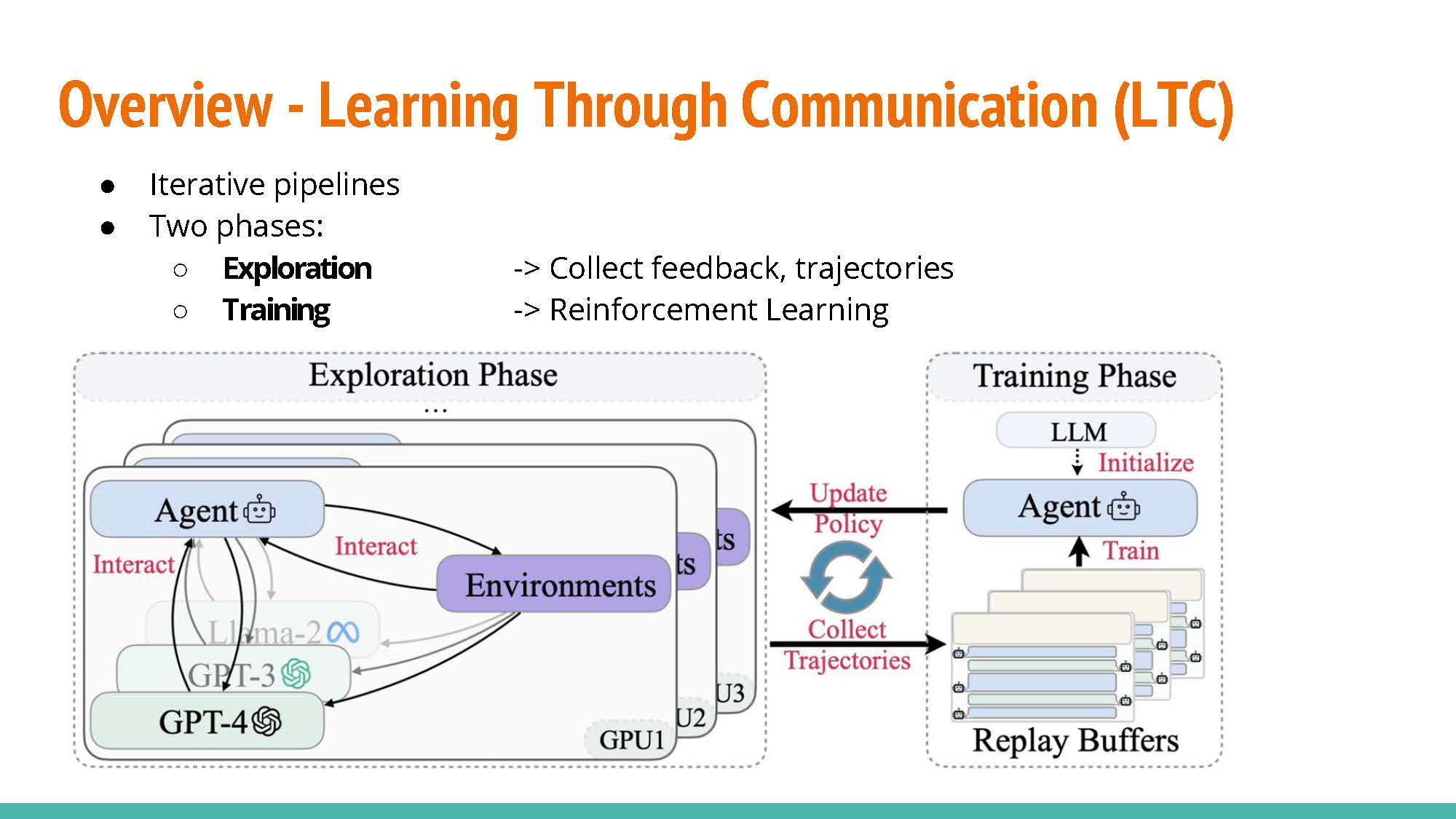 |
This work explored learning through collaboration via multiple types of interaction as shown in the next slide.
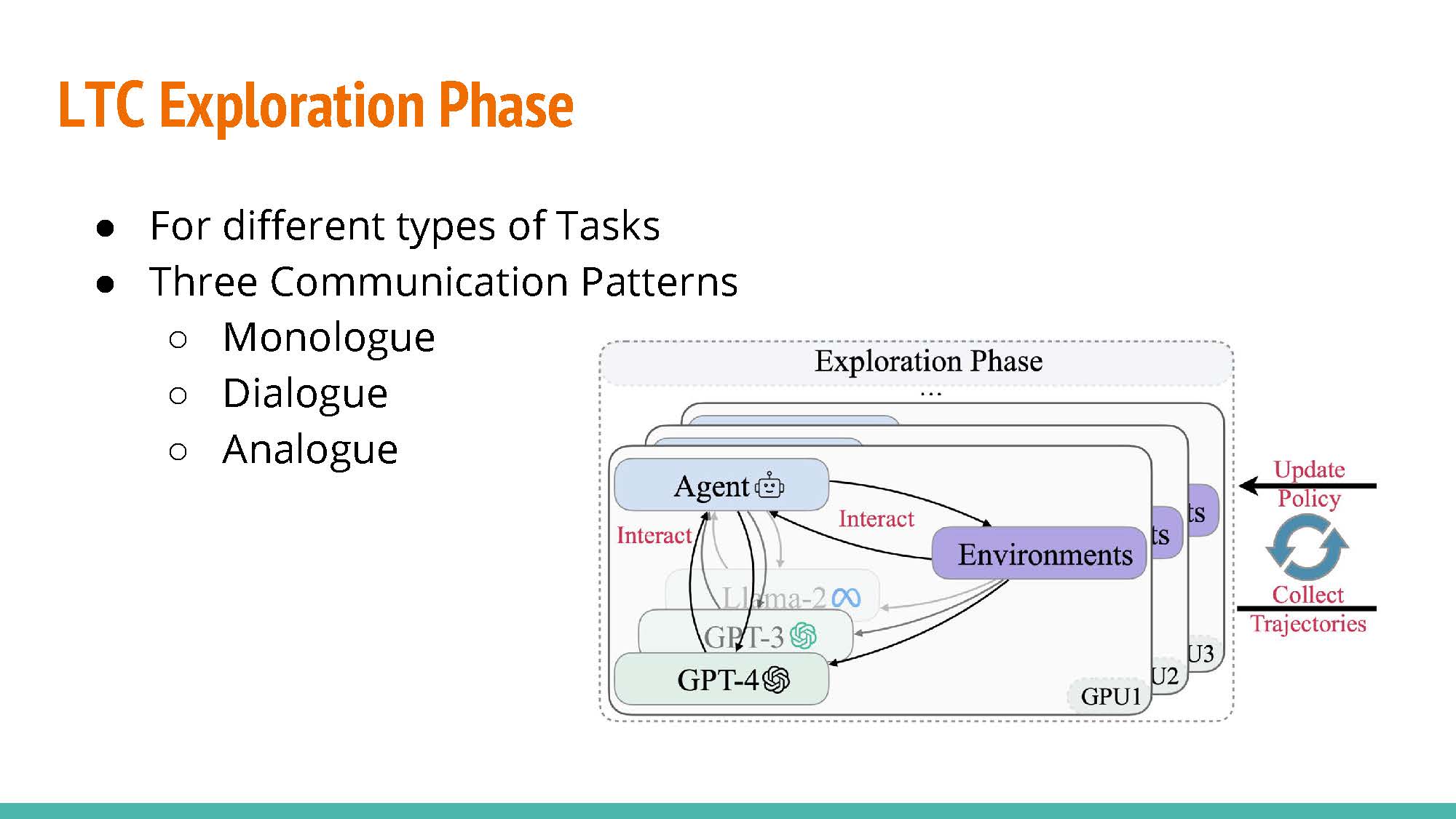 |
 |
 |
 |
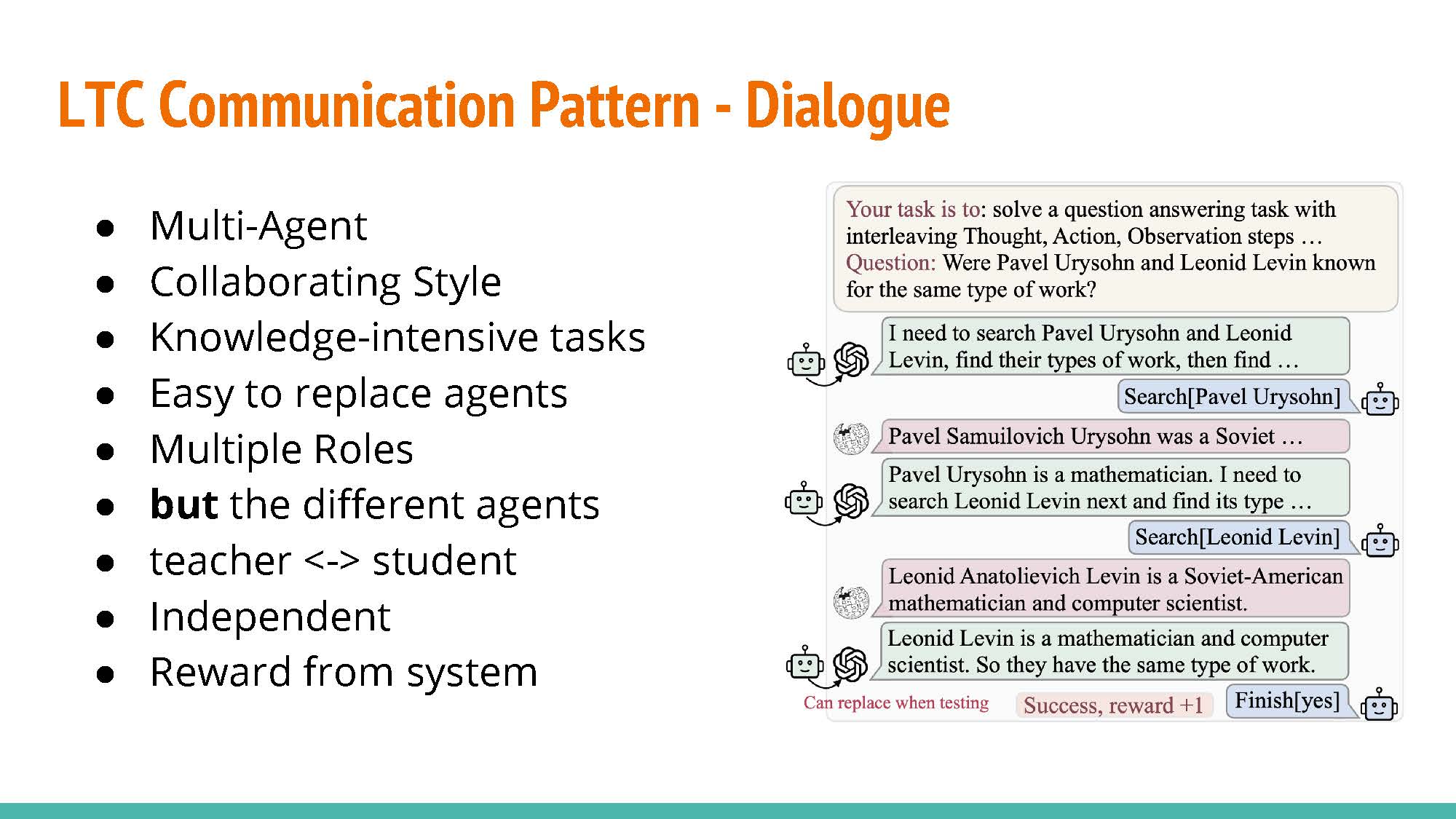
LTC Communication Patters:
- Monologue: Letting an agent train by providing feedback to itself. The agent will play the role of the actor and the instructor.
- Dialogue: As opposed to the previous approach, training is conducted with separate agents acting as the actor and the instructor.
- Analogue: Similar to the former approach, but raining rewards and examples are provided by the instructor agent rather than by the environment.
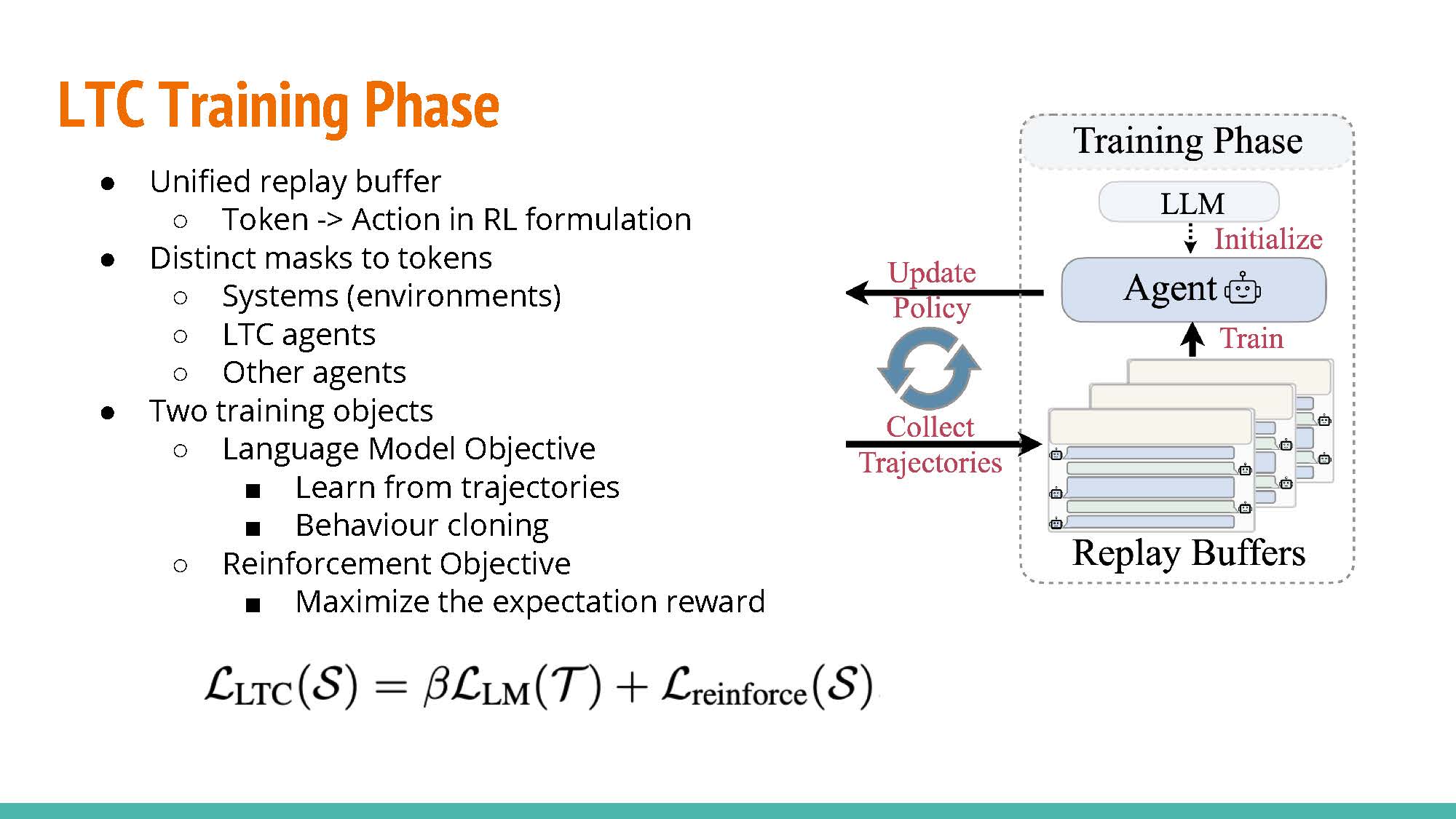 |
The agent model is optimized with the trajectory data collected in the exploration phase. This relies on a multi-objective loss function composed of a standard loss function for unsupervised language model training and a reinforcement objective to maximize the expected reward from previous communication data. Beta acts as a balancing hyper-parameter.
 |
Readings and Discussion Questions
Monday 13 November: Introduction to LLM Agents
Readings
Required: Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv 2023. [PDF]Required: Subbarao Kambhampati. Can LLMs Really Reason and Plan?. Blog@CACM. 2023.Optional: Lilian Wang. LLM Powered Autonomous Agents. Blog. 2023.Optional: Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen. A Survey on Large Language Model based Autonomous Agents. arXiv 2023. [PDF]Optional: Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, Subbarao Kambhampati. On the Planning Abilities of Large Language Models : A Critical Investigation. NeurIPS 2023. [PDF]Optional: Lin Guan, Karthik Valmeekam, Sarath Sreedharan, Subbarao Kambhampati. Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning. NeurIPS 2023. [PDF]
Questions
(Post response by Sunday, 12 November)
- What are the key methodologies or techniques used in the Toolformer paper, and how does the tool use of LLM differ from the existing use of LLM, e.g., prompting, demonstration, etc.?
- Which potential applications or industries could benefit (or suffer) the most from the LLM Agent concept? How might it revolutionize or impact these areas?
- Regarding Can LLMs Really Reason and Plan?, do you agree with the opinion that what LLMs really do is a form of universal approximate retrieval, which was sometimes mistakenly interpreted as reasoning capabilities? What is your perspective on this question?
Wednesday 15 November: Applications of LLM Agents
Readings
Required: Qinlin Zhao, Jindong Wang, Yixuan Zhang, Yiqiao Jin, Kaijie Zhu, Hao Chen, Xing Xie. CompeteAI: Understanding the Competition Behaviors in Large Language Model-based Agents. arXiv 2023. [PDF]Optional: Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, Igor Mordatch. Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv 2023. [PDF]Optional: Kuan Wang, Yadong Lu, Michael Santacroce, Yeyun Gong, Chao Zhang, Yelong Shen. Adapting LLM Agents Through Communication. arXiv 2023. [PDF]Optional: Daniil A. Boiko, Robert MacKnight, Gabe Gomes. Emergent autonomous scientific research capabilities of large language models. arXiv 2023. [PDF]Optional: Yuzhuang Xu, Shuo Wang, Peng Li, Fuwen Luo, Xiaolong Wang, Weidong Liu, Yang Liu. Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf. arXiv 2023. [PDF]
Questions
(Post response by Tuesday, 14 November)
- The CompeteAI: Understanding the Competition Behaviors in Large Language Model-based Agents paper shows that LLM agents can be used for simulating the competition environment. How might the competition behaviors observed in LLM-based agents translate to other real-world applications where strategic competition is critical? Essentially, are there specific characteristics unique to the restaurant setting that might not directly apply to other sectors?
- What are some considerations (ethical or otherwise) that may arise as a result of programming LLMs to compete with each other, especially considering the possibility of this being implemented in real world scenarios? If there are valid concerns, how could the models be calibrated to ensure that the competition remains ethical, preventing the agents from learning and adopting potentially harmful or deceptive strategies?
- Agents can be used in various ways. One way is to make them compete (like in the CompeteAI paper). Instead of competing, how can agents be used in other ways (e.g. by collaborating/communicating with each other), and how might this impact their behavior?
- Given the adaptive nature of LLM-based agents in a competitive environment, how can we ensure transparency and interpretability in the decision-making processes of these agents, so that stakeholders can understand and trust the outcomes of such simulations?