(see bottom for assigned readings and questions)
Capabilities of LLMs (Week 4)
Monday, September 18
Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, Xia Hu. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. April 2023. https://arxiv.org/abs/2304.13712
This discussion was essential to highlight the distinction between large language models (LLMs) and fine-tuned models. The paper defines LLMs as models trained on large amounts of data without a particular domain of application in mind and fine-tuned models as models trained on some general data in addition to data from a specific domain in which they will perform a particular task. They also highlighted a rule of thumb from the paper that LLMs typically have more than 20 billion parameters whereas fine-tuned models have fewer than 20 billion parameters.
The presenters then discussed how to go about choosing the model that is best for a task when there are so many available. They explored two ways of approaching this problem: one that considers the data, and another that considers the task.
The presenters highlighted three types of data to consider for a task: the pre-training data, the fine-tuning data, and the test data. If there is a model already pre-trained on data that is relevant to the task at hand, that model might be a good choice. In order for a dataset to be conducive to fine-tuning a model, the data must be labeled and that there must be enough of it to sufficiently train the model. Otherwise, training an LLM would be better. The presenters noted, however, that fine-tuned models have been shown to perform better than LLMs on specific tasks when they have sufficient data to train on.
The following Figure 1 shows that fine-tuned models performed better than LLMs after being trained on enough data:
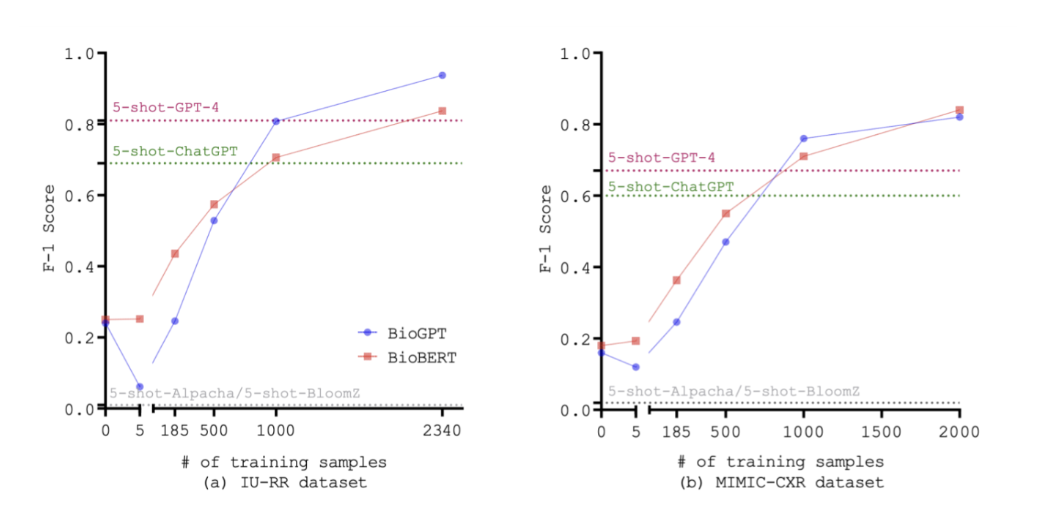 |
Figure 1 (Image source) |
LLMs and fine-tuned models perform better on different tasks. According to a study from the paper Benchmarking Large Language Models for News Summarization 1, LLMs perform better than fine-tuned models on text summarization according to the preferences of human raters. Additionally, LLMs perform better on tasks that require large amounts of knowledge from a variety of domains2. In machine translation, however, fine-tuned models generally do better than LLMs, although they only do slightly better in low-resource settings2. Additionally, the presenters explained that fine-tuned models and LLMs have similar performance when the task only requires very specific knowledge.
The presenters then posed the following question to the class: “How could we enhance LLM in the scenario where the required knowledge does not match their learned knowledge?” The class formed four groups to discuss the question. Each group then shared a summary of what they had discussed:
Group 1: Discussed enhancements in both training and testing. For testing, use intentional prompts to get the knowledge you want from the model. For training, adding more training data, using a knowledge graph to classify knowledge into different clusters for ease of search, and using a plug-in, as mentioned in the GitHub discussion.
Group 2: Advocated for enhancement through the model’s ability to retrieve information from external sources and undergo fine-tuning.
Group 3: Emphasized the significance of using more extensive datasets and guiding models through example-based prompts to extract additional knowledge from the available data.
Group 4: Proposed refining model performance through fine-tuning and deliberately specifying the model’s role within a chat setting to steer it toward specific tasks.
The presenters also mentioned that LLMs perform arithmetic better as they grow larger and that LLMs are better at commonsense reasoning than fine-tuned models3.
ChatGPT Plug-Ins
The presenters then moved to a discussion of ChatGPT plug-ins. They established that LLMs are not able to keep up with current knowledge and facts and that they mainly handle text data as opposed to image data, audio, and other data formats. They also explained that while LLMs may be able to generate instructions for a human to follow to complete a task, they are often unable to follow those instructions and complete the tasks themselves. This is where plug-ins come in.
Plug-ins allow LLMs to access data outside of what they have already learned, for example, by searching the web. Plug-ins can enable ChatGPT to search the web (https://openai.com/blog/chatgpt-plugins#browsing) and write code (https://openai.com/blog/chatgpt-plugins#code-interpreter). They also showed a video of how ChatGPT can use plug-ins from outside OpenAI to complete tasks with specific instructions, namely, finding a restaurant, then a recipe, then calculating the number of calories in the recipe (https://openai.com/blog/chatgpt-plugins#third-party-plugins).
The class then formed groups and spent 25 minutes designing custom plug-ins. Each group then shared their plug-in with the class:
Group 1: Envisioned a plug-in that allows a user to make DIY furniture or buy new furniture by submitting an image of something they would like to make from scratch or buy and returning either a link to a similar piece of furniture or a video/instructions on how to build a piece of furniture similar to the one in their image (Figure 2).
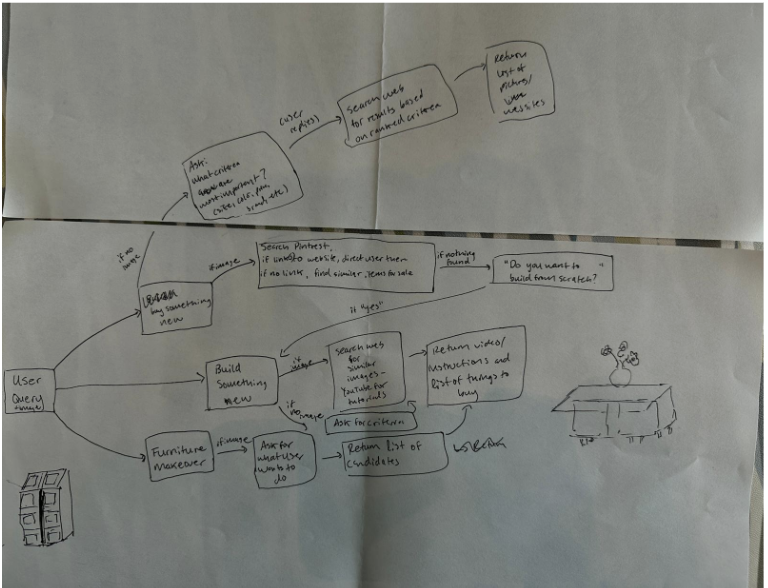 |
Figure 2 DIY Furniture Plug-In |
Group 2: Suggested a plug-in that generates the profile of a fake person with a fake social media account. Essentially, it aimed to create a convincing online persona that would resemble a real person but was entirely fictional. (Such a plug-in, obviously, raises some serious ethical concerns and could be used for some legitimate purposes, but many malign ones!)
Group 3: Created a plug-in that uses a person’s portfolio/resume to match them with different jobs serving as an ultimate career support tool (Figure 3). It assisted users in job search by matching them with relevant job openings, provided tailored preparation materials for interviews, offered resume/portfolio editing guidance, and provided opportunities to expand their professional network. Essentially, it aimed to equip individuals with the tools and resources needed to enhance their career prospects.
 |
Figure 3 Job Hunter Plug-In |
Group 4: Shared the concept of a plug-in that allows a user to find the taxonomy of a particular research paper, and place it in a research area. Moreover, it offered the valuable function of returning related papers, thus assisting users in discovering additional relevant research in their field of interest.
The discussion on Monday concluded with the class appreciating each other’s ideas on the possibilities of using plug-ins but also their limitations and associated risks. This exchange of perspectives and ideas highlighted the creative ways in which technology and AI-driven tools could be used to address various challenges and opportunities across different domains.
Wednesday: Medical Applications of LLMs
Introduction
Wednesday’s class started with warm-up story about a young boy who finally got diagnosed from ChatGPT. He saw 17 doctors over 3 years for chronic pain but they couldn’t diagnosis what made boy painful. One day, his parents explained the boy’s symptom to ChatGPT and they got a reliable answer. They brought this information to a doctor and after several tests, he could finally get a diagnosis which was correct information from ChatGPT. This story presents a bright possibilities for the medical use of Chat GPT.
We also got a simple question and had to solve the problem not using ChatGPT.
 |
Figure 4 |
About 70% of students could get an answer “A” using a simple web search (e.g., duckduckgo or google) at first trial, and 30% of students could get an answer by several attempts.
Later, we were asked to use ChatGPT to get an answer. All students could get a correct answer for at first trial. For a simple question like this, it is unclear if GPT is better than a web search. ChatGPT has been pre-trained from many documents from the web, so it is good at giving general information.
However, if we ask deeper and expertise questions to ChatGPT, it may not give an answer. We indeed need a LLM model which is trained from medical information to get a reliable result. (Note that GPT-4 is already competitive in many ways with models tuneds specifically for medical applications.)
Medical fine-tuned LLMs
There were many attemps to build LLMs trained with medical knowlege. Med-PaLM is one of the representive models, which is fine-tuned PaLM with a medical knowledge. Figure 5 showed that Med-PalM scored 67.2% on USMLE-type questions in the MedQA dataset. Considering that approximate medical pass mark was 60%, Med-PalM was the first LLM model who passed the approximate medical pass mark by Dec 22.
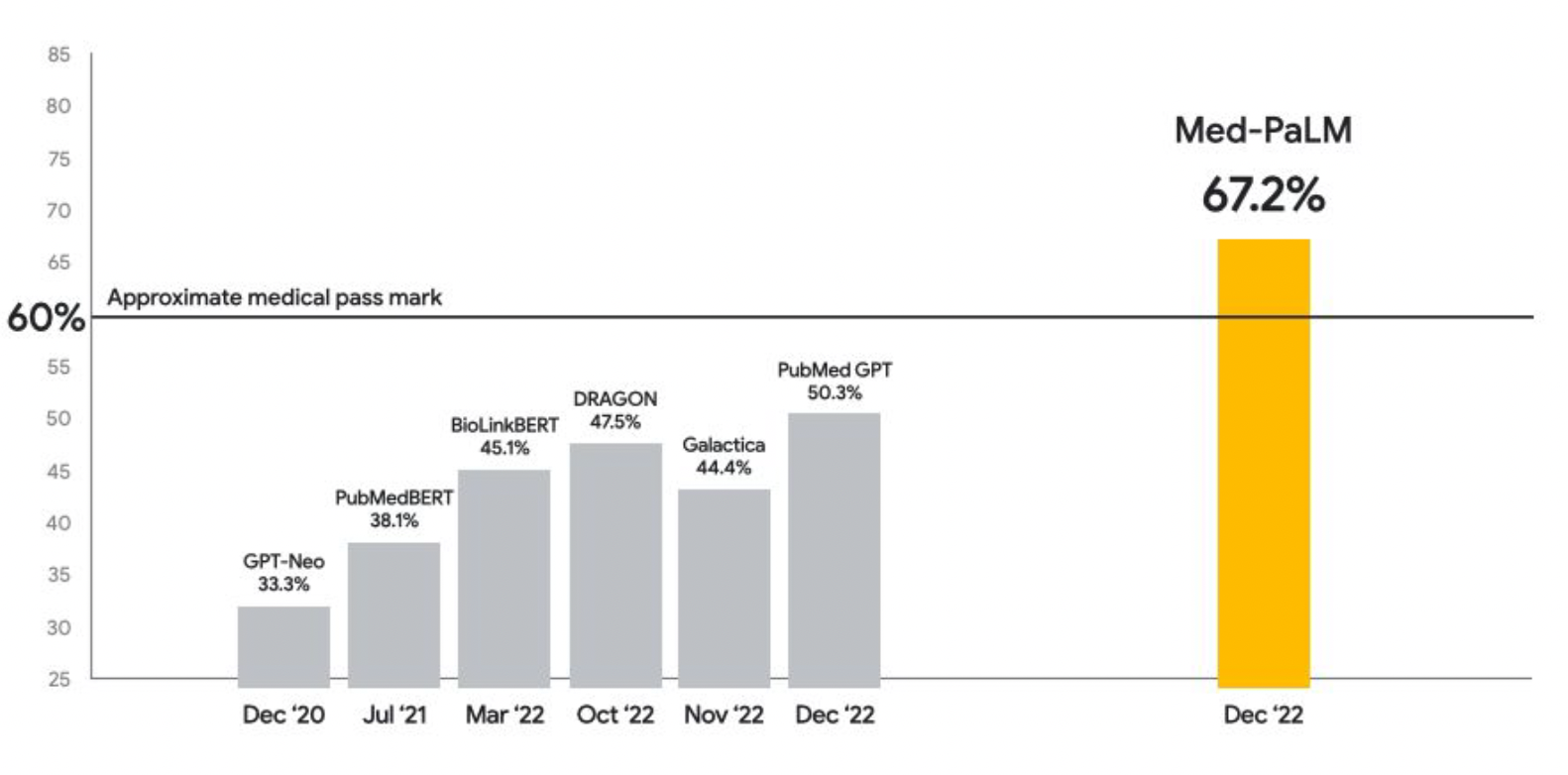 |
Figure 5 (Image source) |
Recently researchers developed Med-PaLM2. They trained PaLM2 with more medical data and upgraded. Figure 6 shows the brief explaination of how Med-PaLM2 was trained. As a result of training fine-tuned with more and better medical information, it could achieve significant improvement.
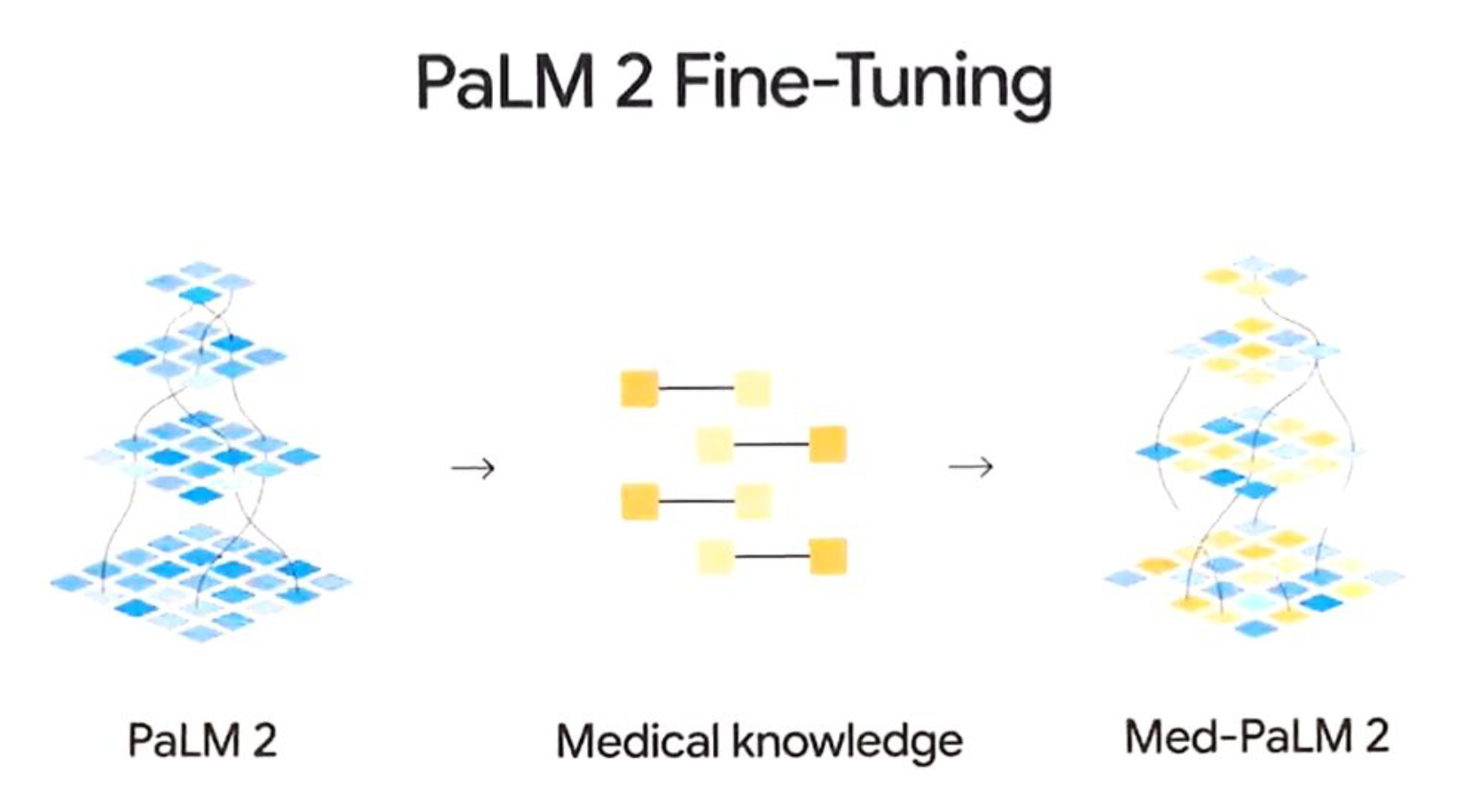 |
Figure 6 (Image source) |
The researchers had a same experiment. Figure 7 showed that Med-PaLM2 scored an accuracy of 86.5% on USMLE-type-questions in the MedQA dataset. Compared with other LLM performance before 2023, Med-PaLM2 was the first LLM to reach expert performance.
In comparison to human physicians in High Quality Answer Traits, Med-PaLM2 showed better reflects consensus, better reading comprehension, better knowledge to recall, and better reasoning.
When they tested Potential Answer Risks, physicians omitted more information, and gave slightly more evidence of demographic bias, and potentially greater extent/likelihood of harm but Med-PaLM2 gave more inaccurate/irrelevant information.
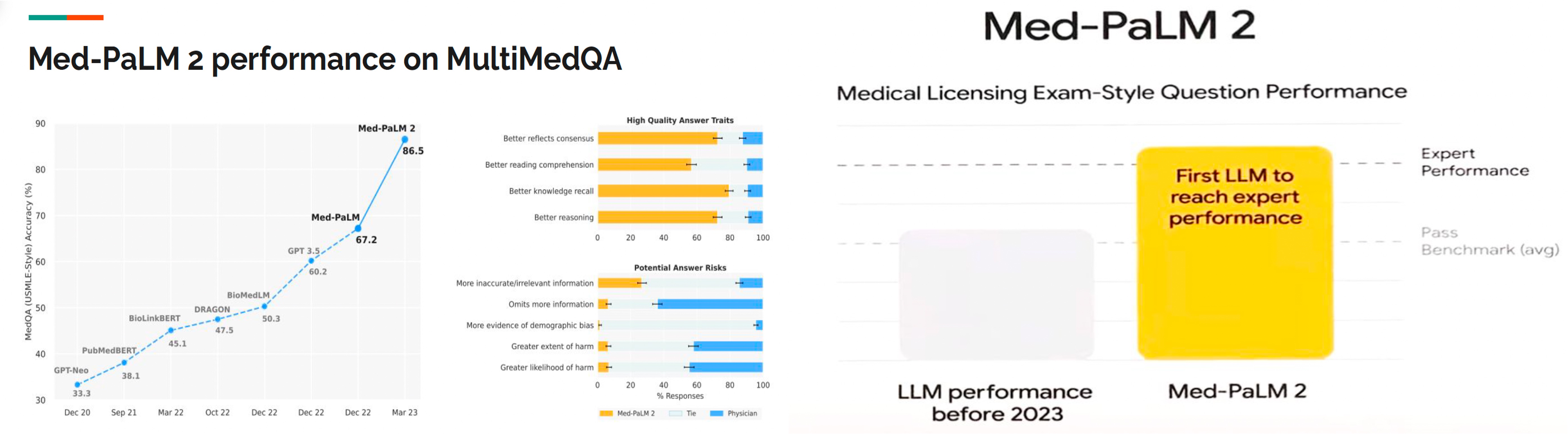 |
Figure 7 (Image source) |
We have seen evidence showing that Med-PaLM2 performs very well, but this is just a starting point for the discussion of how AI should be used in healthcare.
Presenter suggested the one way of increasing the capabilities of Med-LLMs. Extending input data from language to other source of data like image, LLMs could understand better about the condition of patients and give more correct diagnosis. Presenter introduced a multimodal version Med-PaLM, in figure 8. Accuracy of the diagonsis is mainly based on how input data contain the precise information about the patient, so as LLM model could be trained through those multimodal material, there would be larger chances of increasing the capabilities.
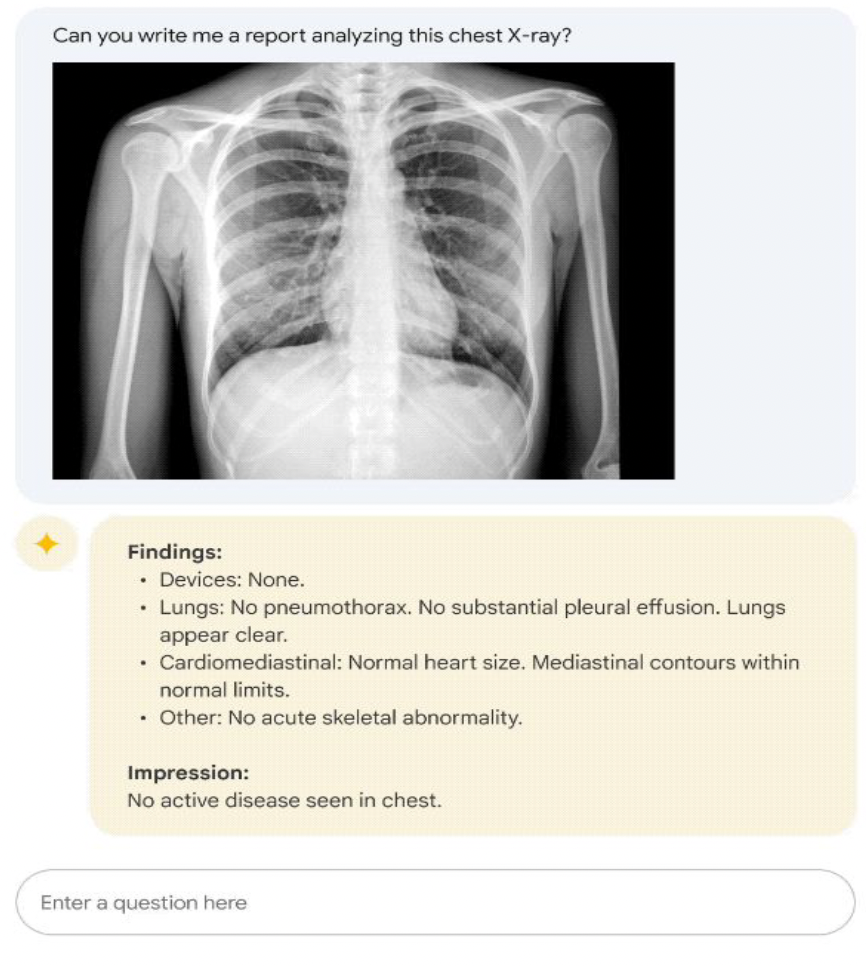 |
Figure 8 (Image source) |
Also presenter gave a data about physician evaluation on Multi-Med QA and adversarial Qustion to compare the physician, Med-PaLM1, and Med-PaLM2 as you can see in figure 9. It showed the significant increased capabilities as Med-PaLM developed to Med-PaLM2. Furthermore, Almost evalution on Med-PaLM2 is within the range of physicians and some of evaluation even exceed physicians. Based on this results, presenter opened a discussion.
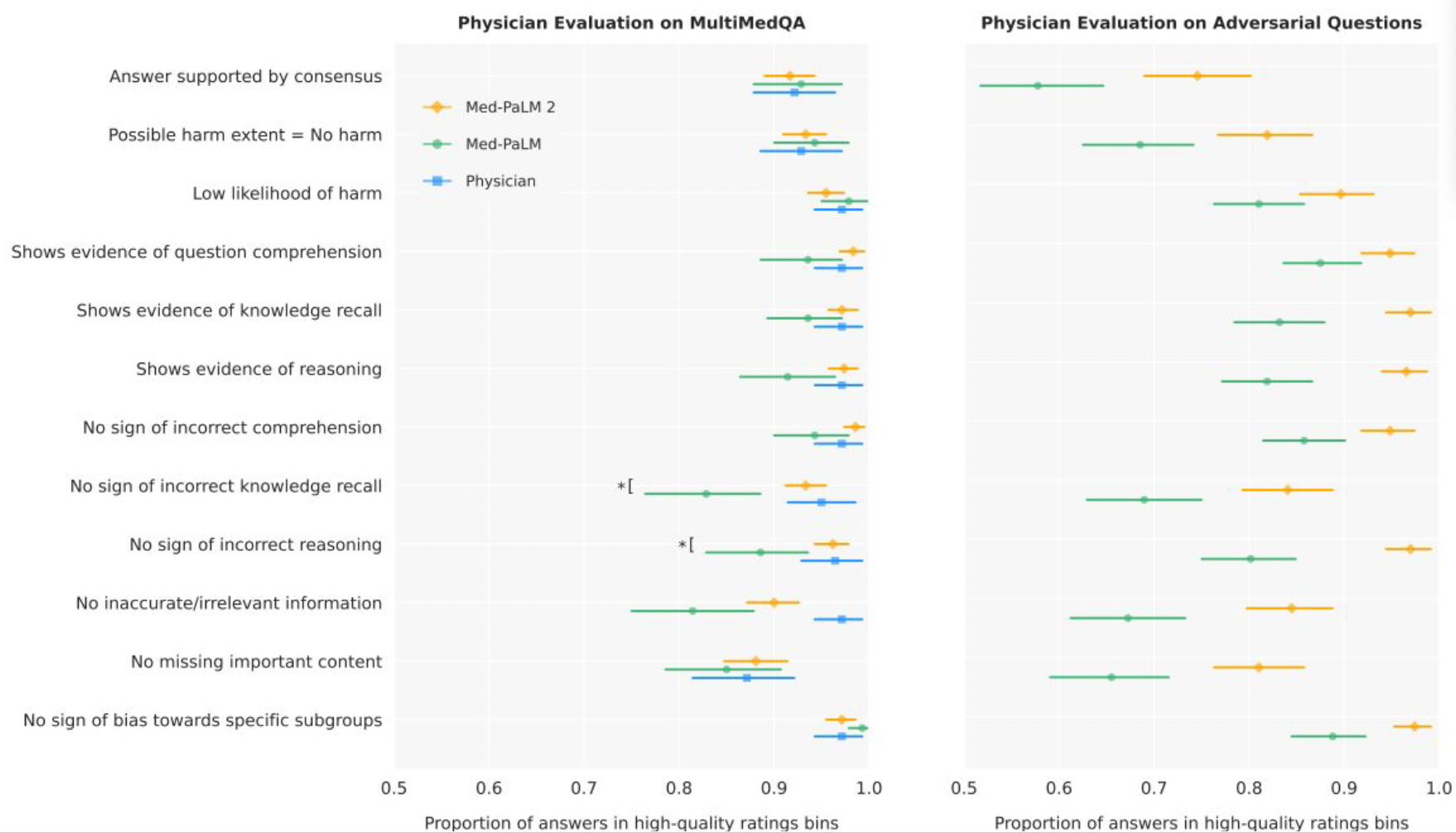 |
Figure 9 (Image source) |
Discussion
What are the potential implications of LLMs reaching or surpassing human expertise in medical knowledge?
The discussion raised more questions than answers:
-
At what point do we trust doctors vs LLMs and to what extent?
-
Are LLMs more convenient than going to a doctor?
-
People will be more prone to self-diagnosis
-
People could be more honest with AI than a human being
-
Should we let AI write prescriptions?
-
How can we truly verify what is right and what is wrong?
-
AI could obviously give a better diagnosis than human whose experiences effect diagnoses
-
What would happen when different Ais give different results?
-
There is a lot of data to train with and fine tuning. Is this worth the time and effort?
-
Who is taking accountability for the mistakes made by AI? If a doctor does something wrong, they can have their license taken, but this is that the case for AI.
-
How can we refine and improve LLMs like Med-PaLM2 to be more effective in healthcare applications?
Readings
Monday:
-
Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, Xia Hu. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. April 2023. https://arxiv.org/abs/2304.13712. [PDF]
-
OpenAI. GPT-4 Technical Report. March 2023. https://arxiv.org/abs/2303.08774 [PDF]
Optionally, also explore https://openai.com/blog/chatgpt-plugins.
Wednesday:
- Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, Mike Schaekermann, Amy Wang, Mohamed Amin, Sami Lachgar, Philip Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Nenad Tomasev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, Vivek Natarajan. Towards Expert-Level Medical Question Answering with Large Language Models https://arxiv.org/abs/2305.09617 [PDF]
Optional Readings:
- Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, Eric Horvitz. Capabilities of GPT-4 on Medical Challenge Problems. March 2023. https://arxiv.org/abs/2303.13375
- Travis Zack, Eric Lehman, Mirac Suzgun, Jorge A. Rodriguez, Leo Anthony Celi, Judy Gichoya, Dan Jurafsky, Peter Szolovits, David W. Bates, Raja-Elie E. Abdulnour, Atul J. Butte, Emily Alsentzer. Coding Inequity: Assessing GPT-4’s Potential for Perpetuating Racial and Gender Biases in Healthcare. July 2023. https://www.medrxiv.org/content/10.1101/2023.07.13.23292577 — This article relates to the underlying biases in the models we talked about this week, but with an application that show clear potential harm resulting from these biases in the form if increased risk of medical misdiagnosis.
Discussion for Monday:
Everyone who is not in either the lead or blogging team for the week should post (in the comments below) an answer to at least one of the questions in this section, or a substantive response to someone else’s comment, or something interesting about the readings that is not covered by these questions. Don’t post duplicates - if others have already posted, you should read their responses before adding your own. Please post your responses to different questions as separate comments.
You should post your initial response before 5:29pm on Sunday, September 17, but feel free (and encouraged!) to continue the discussion after that, including responding to any responses by others to your comments.
- Based on the criterions shown in Figure 2 of [1], imagine a practical scenario and explain why you would choose or not choose using LLMs for your scenario.
- Are plug-ins the future of AGI? Do you think that a company should only focus on building powerful AI systems that does not need any support from plug-ins, or they should only focus on the core system and involve more plug-ins into the ecosystem?
Discussion for Wednesday:
You should post your initial response to one of the questions below or something interesting related to the Wednesday readings before 5:29pm on Tuesday, September 19.
-
What should we do before deploying LLMs in medical diagnosis applications? What (if any) regulations should control or limit how they would be used?
-
With LLMs handling sensitive medical information, how can patient privacy and data security be maintained? What policies and safeguards should be in place to protect patient data?
-
The paper discusses the progress of LLMs towards achieving physician-level performance in medical question answering. What are the potential implications of LLMs reaching or surpassing human expertise in medical knowledge?
-
The paper mentions the importance of safety and minimizing bias in LLM-generated medical information, and the optional reading reports on some experiments that show biases in GPT’s medical diagnoses. Should models be tuned to ignore protected attributes? Should we prevent models from being used in medical applications until these problems can be solved?
-
Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B. Hashimoto. Benchmarking large language models for news summarization, 2023. https://arxiv.org/abs/2301.13848 ↩︎
-
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexan- der Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, An- drew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways, 2022. https://arxiv.org/abs/2204.02311 ↩︎ ↩︎
-
OpenAI. GPT-4 Technical Report. March 2023. https://arxiv.org/abs/2303.08774 ↩︎