(see bottom for assigned readings and questions)
Hallucination (Week 5)
Wednesday, September 27th: Intro to Hallucination
 |
| People Hallucinate Too |
 |
There are three types of hallucinations according to the “Siren's Song in the AI Ocean” paper:
In class, there were dissenting opinions about the definition of hallucination regarding LLMs. One classmate argued how alignment-based hallucination should not be considered as part of the discussion scope, as the model would still be doing what it was intended to be doing (i.e. aligning with the user and/or aligning with the trainer). |
 |
| Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models |
 |
Hallucination Risks |
Group Activity: Engage with ChatGPT to Explore Its Hallucinations (Three Groups Focusing on Different Hallucination Types)
Group 1 focused on "Input-conflict Hallucination". One member narrated a story involving two characters, where one character murdered the other. Contrarily, ChatGPT presented an opposite conclusion. Another member tried to exploit different languages, using two distinct languages that possess similar words.
Group 2 concentrated on "Counter-conflict Hallucination". They described four to five fictitious characters, detailing their interrelationships. Some relationships were deducible, yet the model frequently failed to make a complete set of deductions until explictely prompted to be more complete.
Group 3 delved into "Fact-conflict Hallucination". An illustrative example was when ChatGPT was queried with the fraction "⅓". It offered "0.333" as an approximation. However, when subsequently asked to multiply "0.3333" by "3", it confidently responded with "1". Additional tests included translations between two languages.
Wednesday, October 4th: Hallucination Solutions
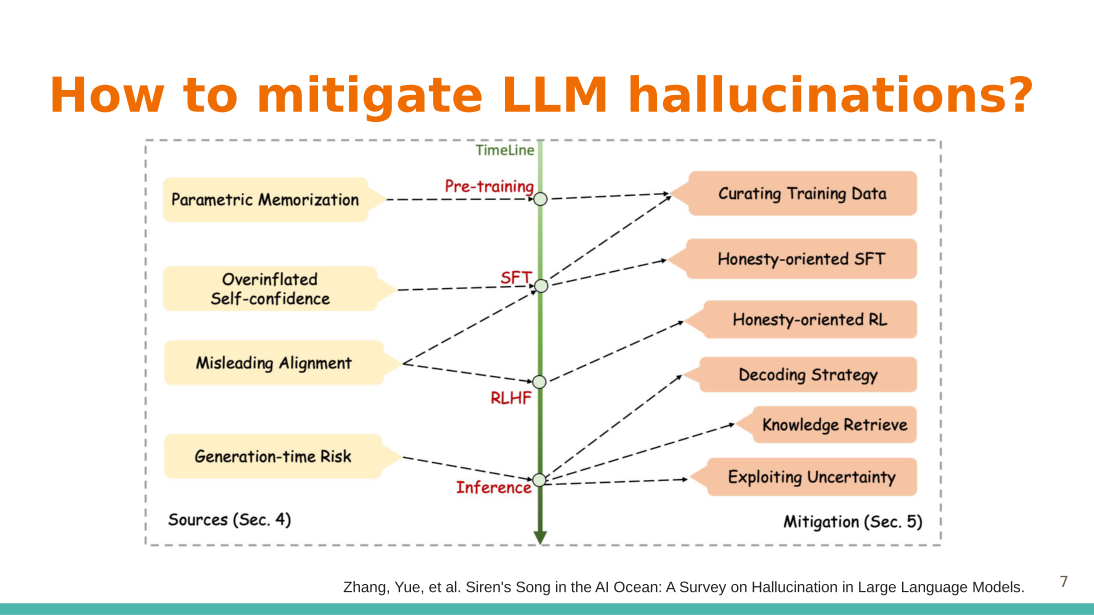 |
| Mitigation Strategies
Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models
For inference, one strategy is to reduce the snowballing of hallucinations by designing a dynamic p-value. The p-value should start off large and shrink as more tokens are generated. Furthermore, introducing new or external knowledge can be done at two different positions: before and after generation. |
 |
|
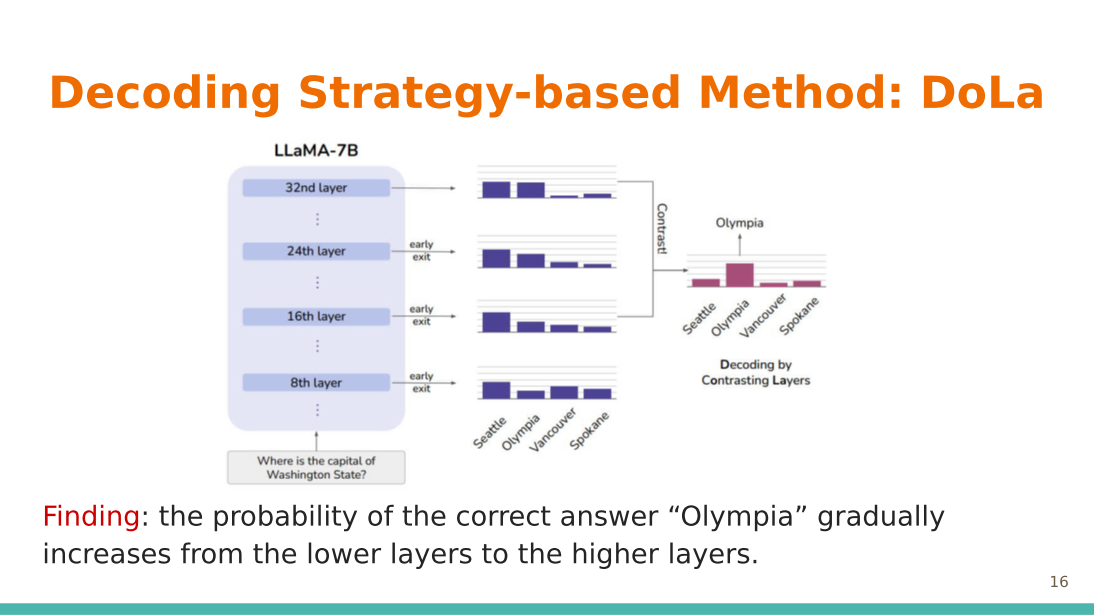
Decoding Contrasting Layers DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models Based on evolving trends, the concept of contrastive decoding is introduced. For example, one might ask, "How do we decide between Seattle or Olympia?" When considering the last layer as a mature layer, it is beneficial to contrast the differences between the preceding layers, which can be deemed as premature. For each of these layers, it is possible to calculate the difference between each probability distribution by comparing mature and premature layers, a process that utilizes the Jensen-Shannon Divergence. Such an approach permits the amplification of the factual knowledge that the model has acquired, thereby enhancing its output generation. |
 |
|
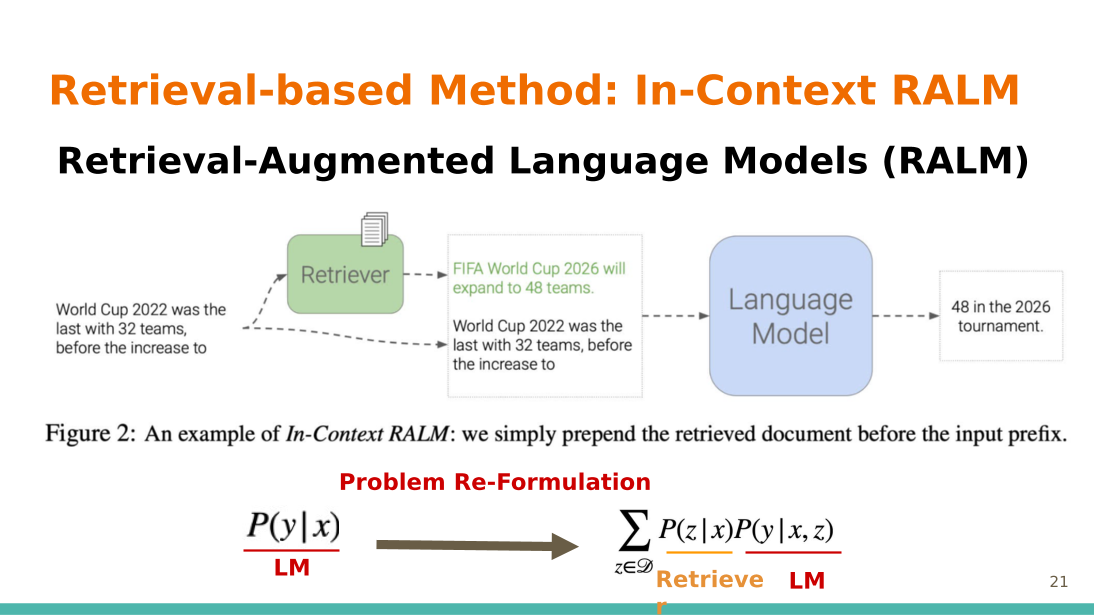
In-Context Retrieval-Augmented Language Models The model parameters are kept frozen. Instead of directly inputting text into the model, the approach first uses retrieval to search for relevant documents from external sources. The findings from these sources are then concatenated with the original text. Re-ranking results from the retrieval model also provides benefits; the exact perplexities can be referred to in the slide. It has been observed that smaller strides can enhance performance, albeit at the cost of increased runtime. The authors have noticed that the information at the end of a query is typically more relevant for output generation. In general, shorter queries tend to outperform longer ones. |
 |
| Benefits of Hallucinations |
Discussion: Based on the sources of hallucination, what methods can be employed to mitigate the hallucination issue?
Group 2: Discussed two papers from this week's reading which highlighted the use of semantic search and the introduction of external context to aid the model. This approach, while useful for diminishing hallucination, heavily depends on external information, which is not effective in generic cases. Further strategies discussed were automated prompt engineering, optimization of user-provided context (noting that extensive contexts can induce hallucination), and using filtering or attention mechanisms to limit the tokens the model processes. From the model's perspective, it is beneficial to employ red-teaming, explore corner cases, and pinpoint domains where hallucinations are prevalent. Notably, responses can vary for an identical prompt. A proposed solution is to generate multiple responses to the same prompt and amalgamate them, perhaps through a majority voting system, to eliminate low-probability hallucinations.
Group 1: Discussed the scarcity of alternatives to the current training dataset. Like Group 2, they also explored the idea of generating multiple responses but suggested allowing the user to select from the array of choices. Another approach discussed was the model admitting uncertainty, stating "I don’t know", rather than producing a hallucination.
Group 3: Addressed inconsistencies in the training data. Emphasized the importance of fine-tuning and ensuring the use of contemporary data. However, they noted that fine-tuning doesn't ensure exclusion of outdated data. It was also advised to source data solely from credible sources. An interesting perspective discussed was utilizing a larger model to verify the smaller model's hallucinations. But a caveat arises: How can one ensure the larger model's accuracy? And if the larger model is deemed superior, why not employ it directly?
Discussion: What are the potential advantages of hallucinations in Large Language Models (LLMs)?
One advantage discussed was that hallucinations "train" users to not blindly trust the model outputs. If such models are blindly trusted, there is a much greater risk associated with their use. If users can conclusively discern, however, that the produced information is fictitious, it could assist in fostering new ideas or fresh perspectives on a given topic. Furthermore, while fake data has potential utility in synthetic data generation, there's a pressing need to remain vigilant regarding the accuracy and plausibility of the data produced.
Readings
For the first class (9/27)
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang et al. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. September 2023. https://arxiv.org/abs/2309.01219
For the second class (10/4)
Choose one (or more) of the following papers to read:
- Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. In-context retrieval-augmented language models. Accepted for publication in TACL 2024.
- Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. September 2023.
Optional Additional Readings
Overview of hallucination
- Vipula Rawte, Amit Sheth, and Amitava Das. A Survey of Hallucination in Large Foundation Models. September 2023.
- Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. Cognitive Mirage: A Review of Hallucinations in Large Language Models. September 2023.
Nick McKenna, Tianyi Li, Liang Cheng, Mohammad Javad Hosseini, Mark Johnson, and Mark Steedman. Sources of Hallucination by Large Language Models on Inference Tasks. May 2023. - Why ChatGPT and Bing Chat are so good at making things up
How to reduce hallucination: Retrieval-augmented LLM
- Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. January 2023.
- Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang et al. Check your facts and try again: Improving large language models with external knowledge and automated feedback. Februrary 2023.
- Akari Asai, Sewon Min, Zexuan Zhong, and Danqi Chen. ACL 2023 Tutorial: Retrieval-based Language Models and Applications. ACL 2023.
How to reduce hallucination: Decoding strategy
- Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale N. Fung, Mohammad Shoeybi, and Bryan Catanzaro. Factuality enhanced language models for open-ended text generation. NeurIPS 2022.
- Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model. June 2023.
Hallucination is not always harmful: Possible use cases of hallucination
- dreamGPT: AI powered inspiration
- Are AI models doomed to always hallucinate?
- OpenAI CEO Sam Altman sees “a lot of value” in AI hallucinations.
Discussion Questions
Everyone who is not in either the lead or blogging team for the week should post (in the comments below) an answer to at least one of the four questions in each section, or a substantive response to someone else’s comment, or something interesting about the readings that is not covered by these questions.
Don’t post duplicates - if others have already posted, you should read their responses before adding your own. Please post your responses to different questions as separate comments.
First section (1 - 4): Before 5:29pm on Tuesday 26 September.
Second section (5 - 9): Before 5:29pm on Tuesday 3 October.
Questions for the first class (9/27)
- What are the risks of hallucinations, especially when LLMs are used in critical applications such as autonomous vehicles, medical diagnosis, or legal analysis?
- What are some potential long-term consequences of allowing LLMs to generate fabricated information without proper detection and mitigation measures in place?
- How can we distinguish between legitimate generalization or “creative writing” and hallucination? Where is the line between expanding on existing knowledge and creating entirely fictional information, and what are the consequences on users?
Questions for the second class (10/4)
- The required reading presents two methods for reducing hallucinations, i.e., introducing external knowledge and designing better decoding strategies. Can you brainstorm or refer to optional readings to explore ways to further mitigate hallucinations? If so, could you elaborate more on your ideas and also discuss the challenges and risks associated with them?
- Among all the mitigation strategies for addressing hallucination (including those introduced in the reading material from the first class), which one do you find most promising, and why?
- Do retrieval-augmented LLMs pose any risks or potential negative consequences despite their ability to mitigate LLM hallucinations through the use of external knowledge?
- The method proposed by DoLa seems quite simple but effective. Where do you think the authors of DoLa get the inspiration for their idea?