Note: since the topics were unrelated, Week 14 is split into two posts:
Monday, November 27: Multimodal Models
Today’s topic is how to improve model performance by combining multiple modes.
 |
We will first introduce the multimodal foundations and then center around CLIP, which is the most famous vision-language model.
 |
We live in a multimodal world, and our brains naturally learn to process multiple sensory signals received from the environment to help us make sense of the world around us. More specifically, vision is a large portion of how humans perceive, while language is a large portion of how humans communicate.
 |
When we talk about vision-language, there are two types of interations to consider: one is how can we produce visual data, and another is how can we consume visual information.
 |
For visual generation, popular models include GAN and diffusion models. What makes it multi-modal is that we can use other modalities to control the image we want to generate, for example, the text-to-image methods that can use text-conditioned visual generation, such as stable diffusion.
 |
Another approach focuses on visual understanding, which studies how can we consume the visual information from the image, and further, how can we consume the audio, image, and different modalities from our surrounding environment.
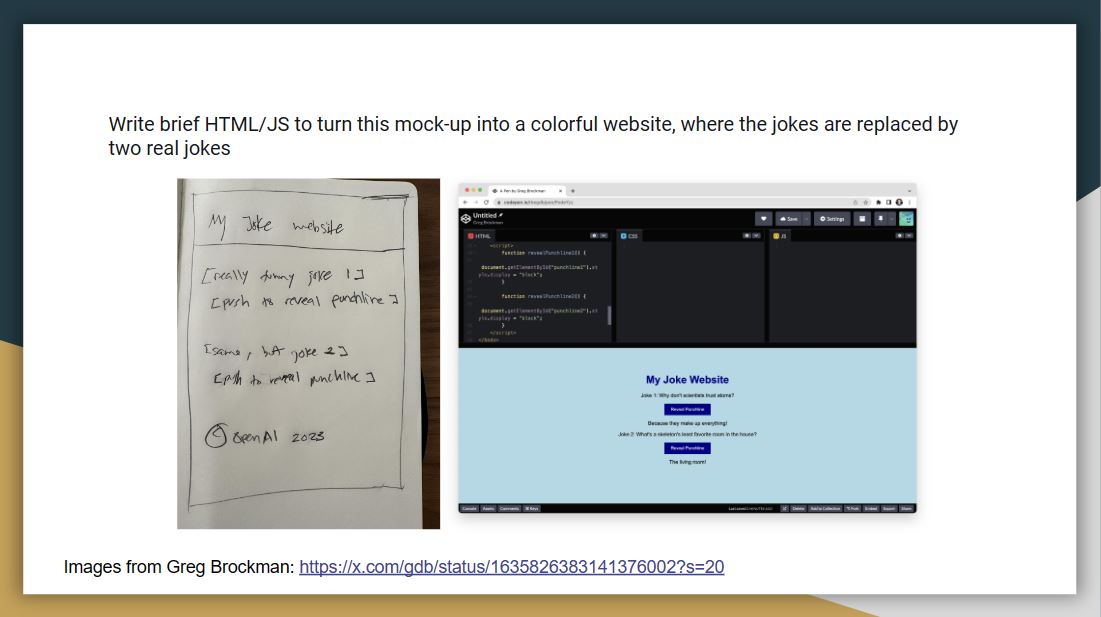 |
Greg Brockman, who is one of the founders of OpenAI, showed ChatGPT a diagram of my joke website, which he sketched with a pencil. Then, ChatGPT outputs a functional website. This is quite remarkable as you can start to plug images into the language models.
Link: https://x.com/gdb/status/1635826383141376002?s=20.
 |
When we see the text “Sunshine, Sunny beach, Coconut, Straw hat”, we can visualize a picture of a beach with these components. This is because our mind not only receives multimodal information but also somehow aligns these modalities.
 |
Now we move to the detailed algorithm of vision-language models. There are particular vision-language problem spaces or representative tasks that these models try to solve.
 |
The first question is how to train a vision-language model. We will discuss supervised pre-training and contrastive language-image pre-training, which is also known as CLIP.
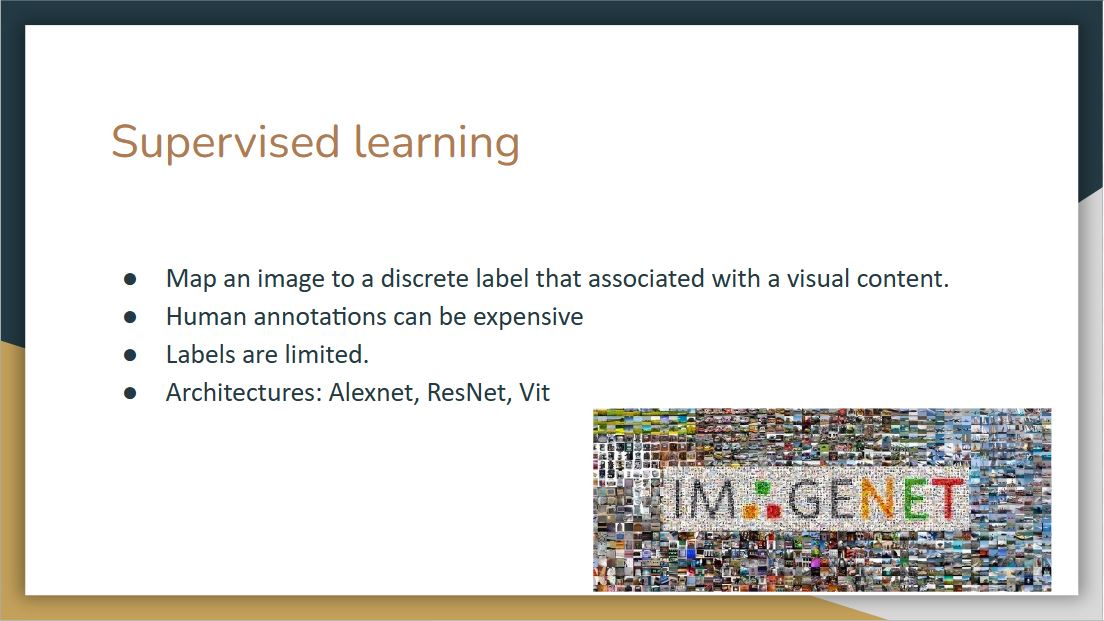 |
Supervised learning will map an image to a discrete label that is associated with visual content. The drawback here is that we always need labeled data. However, human annotations can be expensive and labels are limited.
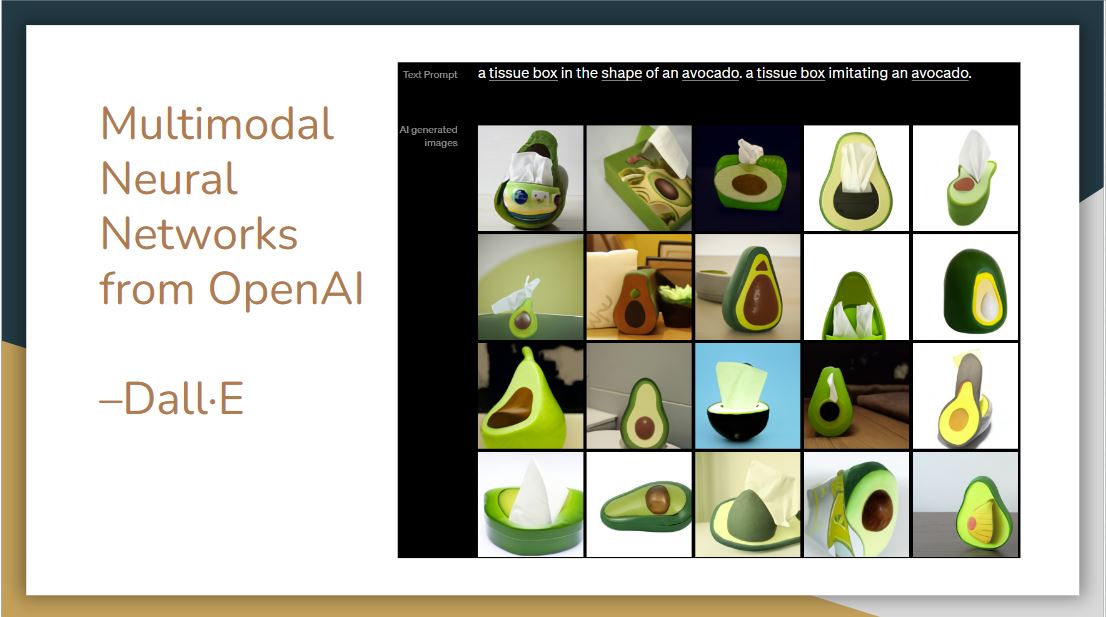 |
The supervised learning method was deployed first. In 2021, OpenAI released Dall-E, which is a generative model that uses transformer architecture like GPT3. The model receives both text and image in the training process, and it can generate images from scratch based on natural language input.
As seen in the images above, it can combine disparate ideas to synthesize objects, even some of them are unlikely to exist in the real world.
CLIP
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021. PDF
 |
Different from Dall-E, CLIP takes an image and text and connects them in non-generative way. The idea is that we can take an image, and the model can predict the text along with it.
Traditional image classification models are trained to identify objects from a predefined set of categories, for example, there are about 1000 categories in the ImageNet challenge. CLIP is trained to understand the semantics of images and text together. It is trained with a huge amount of data, 400 million images on the web and corresponding text data, and it can perform object identification in any category without re-training.
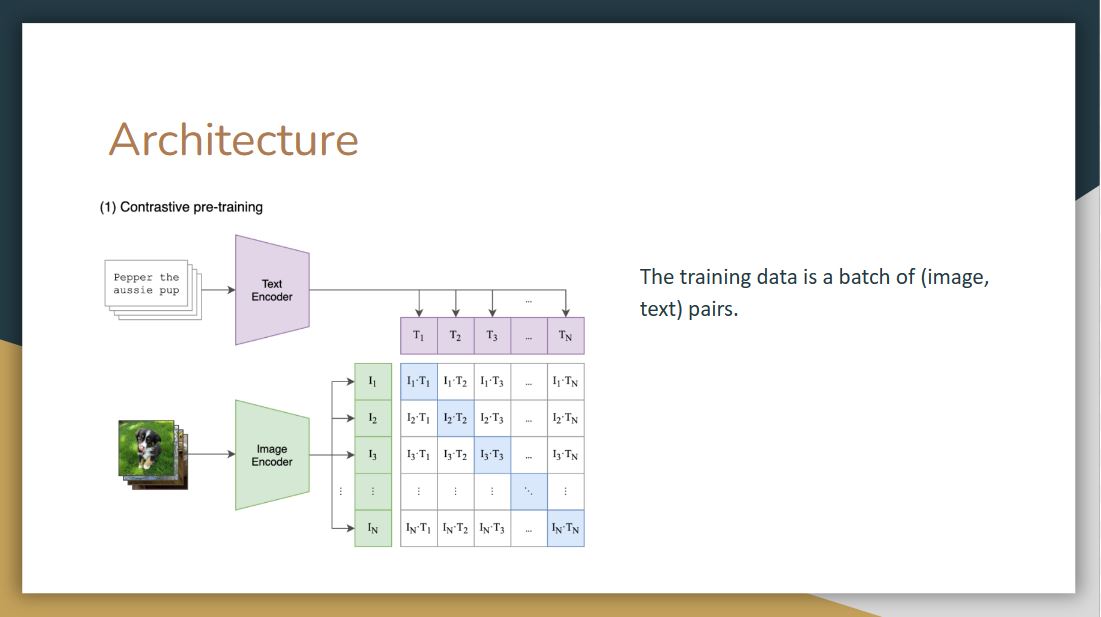 |
Since CLIP was trained using a combination of image and text, the training data is a batch of (image, text) pairs.
On top we have labels that belong to each image, the model tokenize it, passes it to text encoder, performs linear projection, and passes it along to a contrastive embedding screen. It does the same for images.
Then, in the contrastive embedding screen, the model takes the inner product of image vector and text vector. In contrastive learning, we want to increase the values of these blue squares to 1, which are original image and text pairs, and decrease the values of the white squares, which are not the classes they belong to. To achieve this, they compute the loss of these image-text vectors and text-image vectors and do back propagation
 |
We now elaborate more on the loss function of this training process. We have two vectors (text, image) here, $v$ represents the text vector, and $u$ represents the image vector, and $\tau$ here is a trainable parameter.
In the first text-to-image loss function, they take the cosine similarities of these two vectors, sum up all the rows in the denominator and normalized via softmax. As we can see it is an asymmetric problem, so to compute the image-to-text loss function, they sum up all the columns instead of the rows
After that, they compute a cross-entropy loss of these two probability distributions, sum up all the batches, and then average it out to get the final loss function.
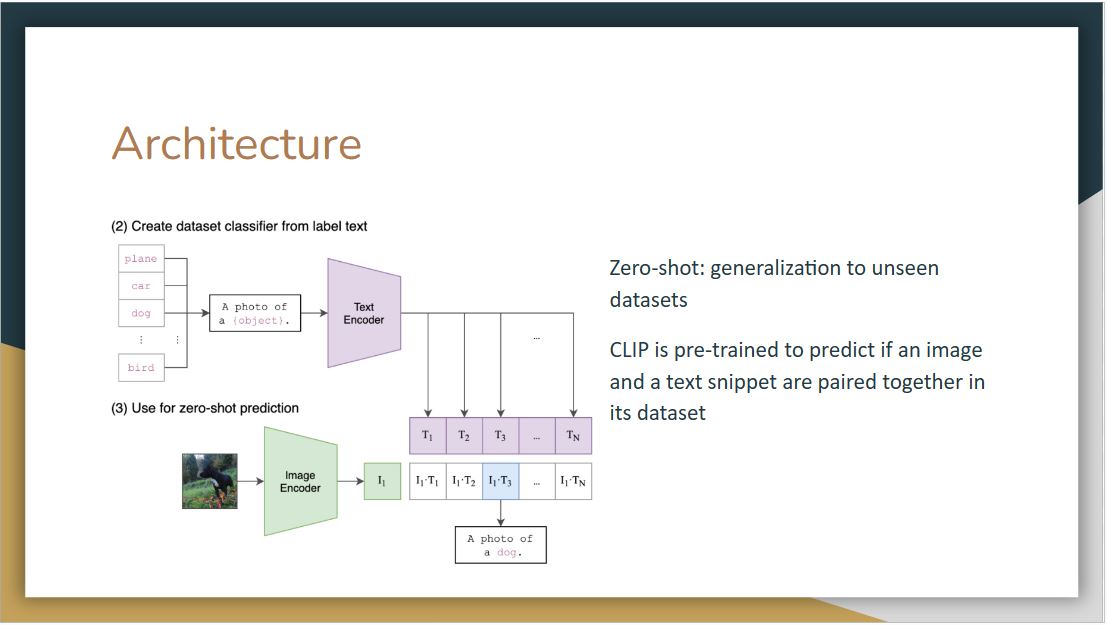 |
After pre-training, the second and third step are for the object identification. We have a new dataset with different classes and want to test CLIP on it. In step 2, we need to pass these classes to the pre-trained text encoder. Instead of passing class names alone, they use a prompt template, making a sentence out of these class names. Then the model will perform the same linear projection as in the pre-training and pass it into a contrastive space
Then in Step 3, we take the image we want to predict, pass it into the image encoder, do linear projection, go into the contrastive embedding space and take the inner products of this image vector and all text vectors in Step 2. The final prediction output will be the one that has the highest cosine similarity.
 |
The authors share three main ideas behind this work:
-
The need of a sufficiently large dataset. The simple truth is that existing manually labeled datasets are just way too small (100k samples) for training a natural language supervised model on the scale of GPT. The intuition is that the required dataset already exists on the web without the need to label data manually. So they created a new dataset of 400 million (image, text) pairs collected from a variety of publicly available sources on the Internet.
-
Efficient pre-training method. After experimenting with class-label prediction, the authors realized that the key to success was in predicting only which text as a whole is paired with which image, not the exact word of that text. This discovery led to the use of the loss function we introduced earlier, such that the cosine similarity for each correct pair of embeddings is maximized, and the cosine similarity of the rest of the pairings are minimized.
-
Using transformers. After some experiments, they selected a transformer as text encoder, and leave two options for image encoder. The image encoder is either a Vision Transformer or a modified ResNet-D with attention pooling instead of global average pooling.
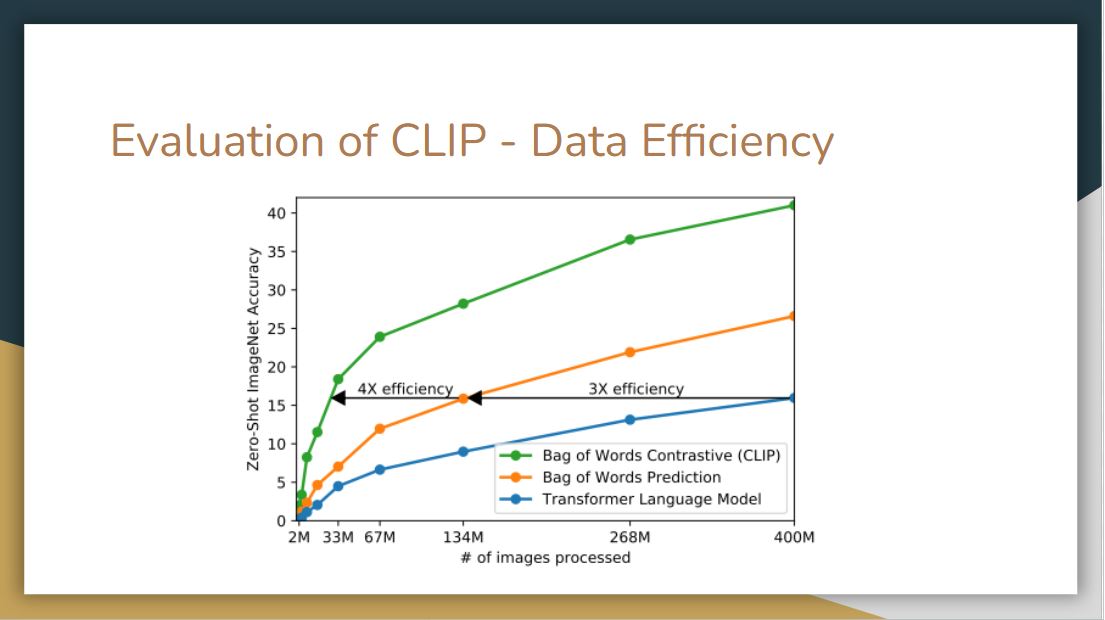 |
The figure above shows that CLIP is by far much more data-efficient than the other methods.
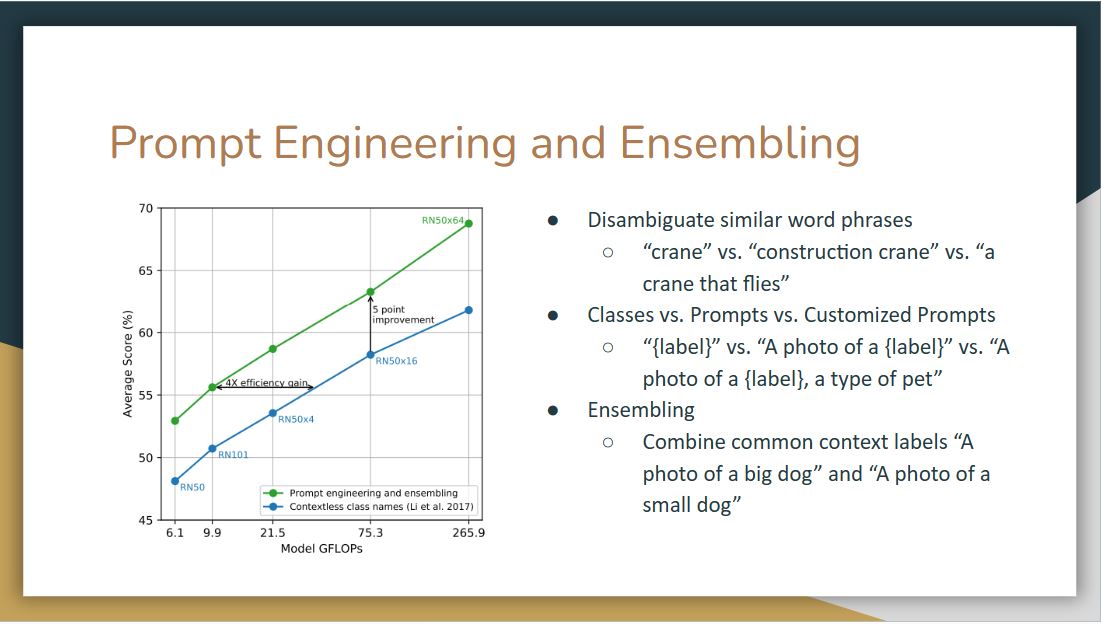 |
With prompt engineering and ensembling, models are more likely to achieve higher accuracy score rather than just simply having contextless class names.
One observation is that CLIP performs poorly on differentiating word sense when there’s only a label without context. For example, the label “crane” can mean construction crane or a crane that flies.
Another observation is that in their pre-training dataset text, it is relatively rare to see an image with just a single word as a label. So to bridge the distribution gap, they use a prompt template. Instead of a single label, they use template sentences like “a photo of a label”. They also found customizing the prompt text to each task can further improve performance.
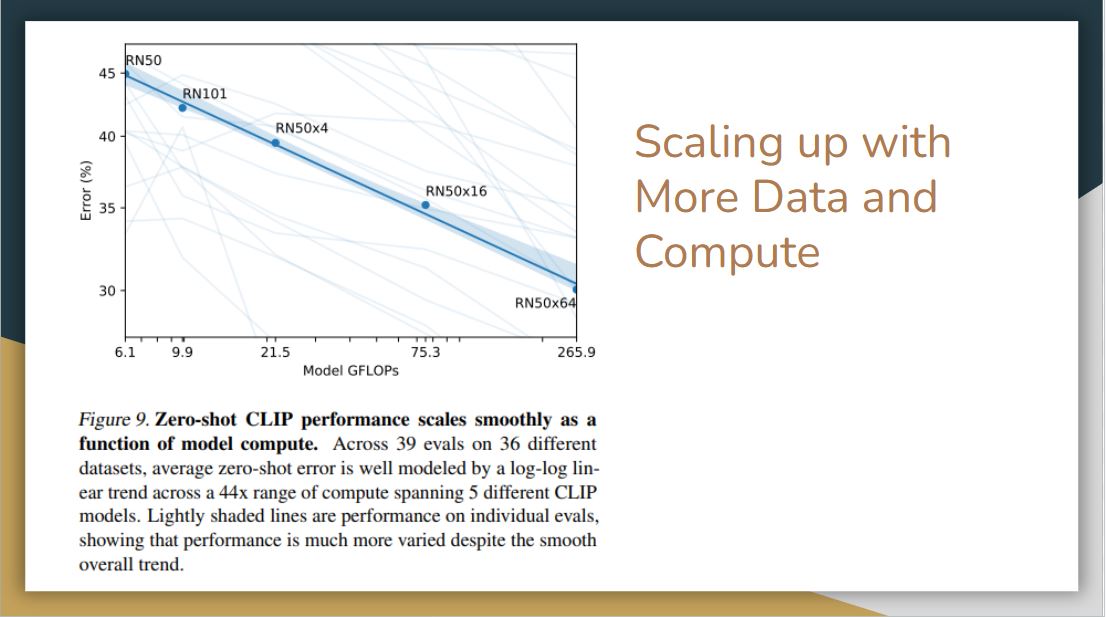 |
As we can see the error rate decreases smoothly as a function of model compute. However, they do note that there is lots of variance, this curve is the average. For individual datasets, it varies widely. It may be due to how the dataset is selected, how the prompt is engineered, or other unknown factors.
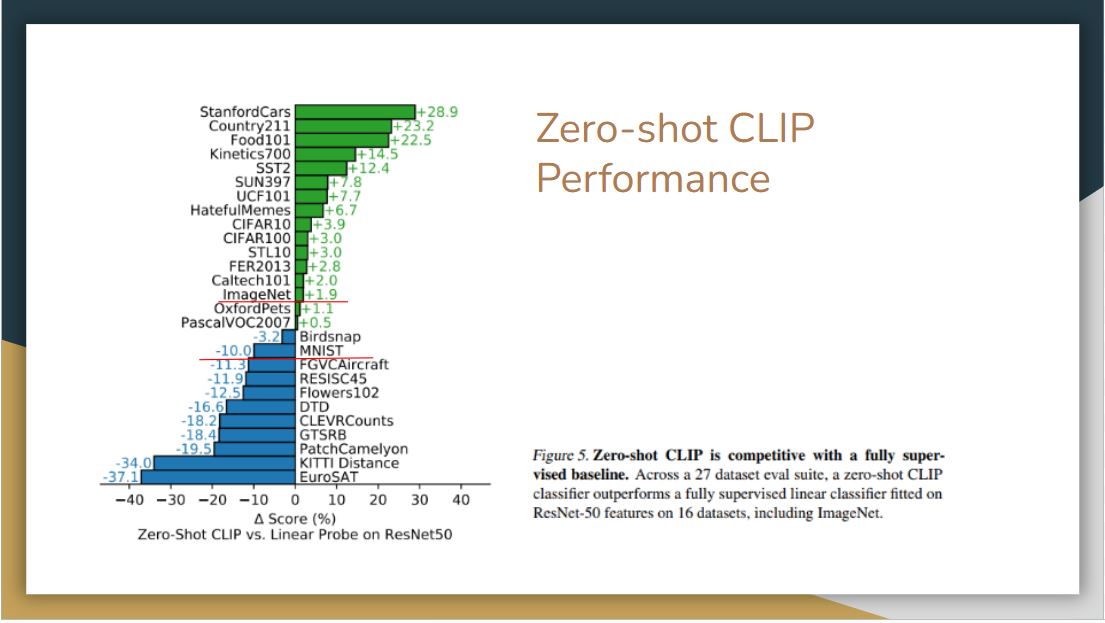 |
For the evaluation in terms of performance, CLIP is compared with a linear probe on ResNet50. It is pretty impressive that zero-shot CLIP outperforms a fully trained model on many of the dataset, including ImageNet.
On the other side, CLIP is weak on several specialized, complex, or abstract tasks such as EuroSAT (satellite image classification), KITTI Distance (recognizing distance to the nearest car). This may because these are not the kinds of text and image found frequently on the Internet, or that these tasks are different enough from common image tasks but simple enough for a custom-trained model to do well.
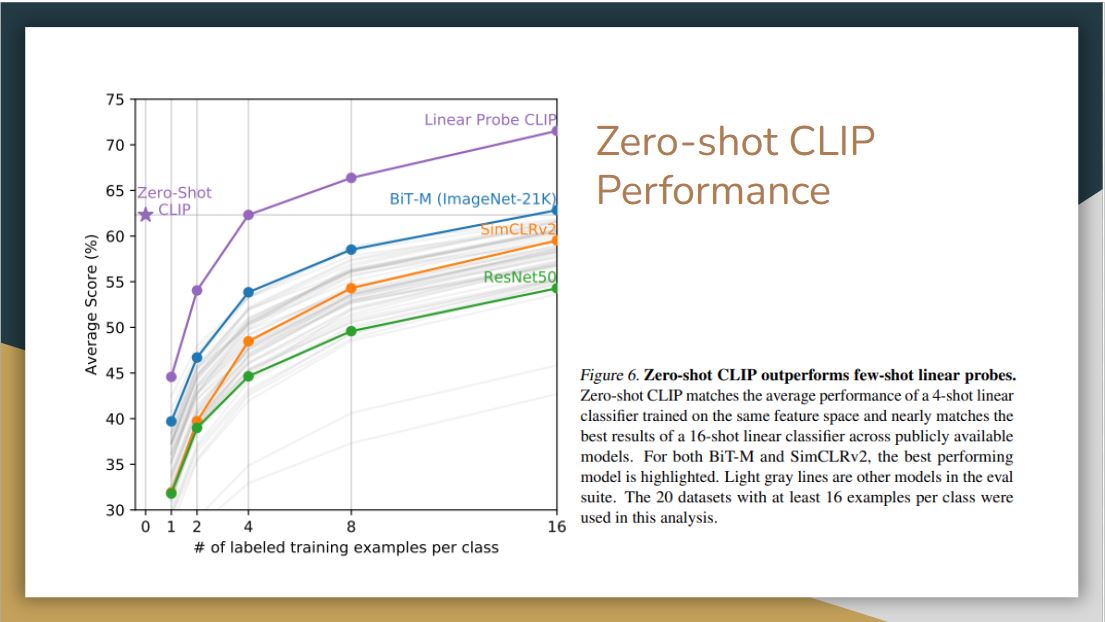 |
Here we compare zero-shot CLIP with few-shot linear probes. This is where pre-training really comes in, as the model only see few examples per class.
Surprisingly, a zero-shot CLIP is comparable to a 16-shot BiT-M model, which is one of the best open models that does transfer learning in computer vision. If we linear probe the CLIP model, then it way outperform these other linear probe models.
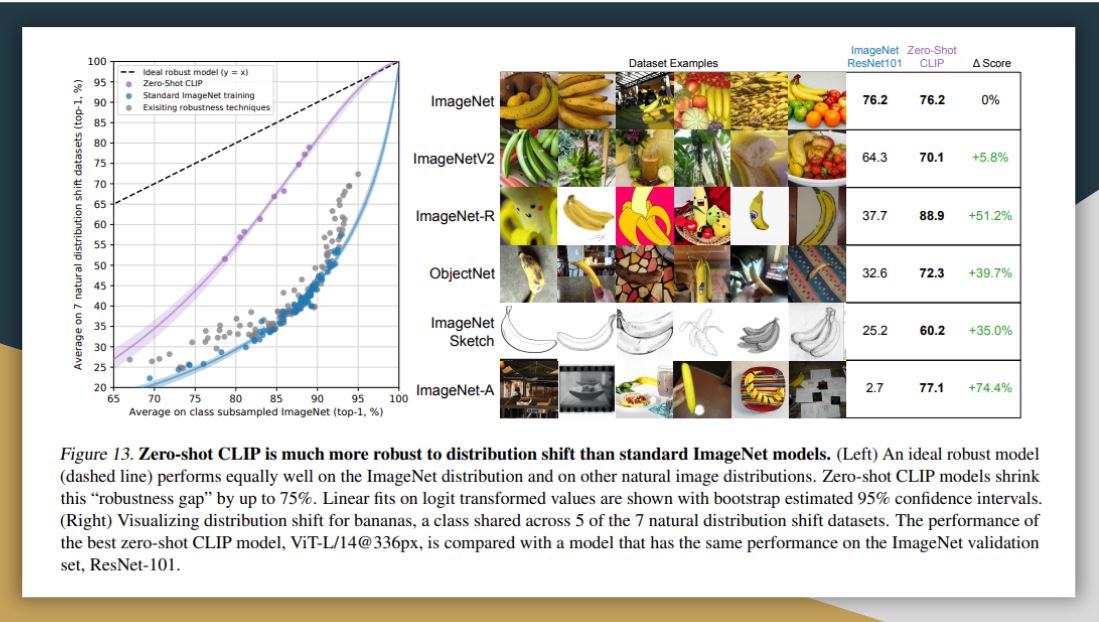 |
They also evaluate CLIP in terms of its robustness to perturbations. Here they compare zero-shot CLIP to models that have been trained on ImageNet, finding that zero-shot clip matches the performance of ResNet-101. As this classifier degrades as we go for harder and harder datasets overall, CLIP is more robust. This suggests that representation in CLIP should be nuanced enough, so it can pick up on different features than only distinguishing banana from other classes in the ImageNet dataset.
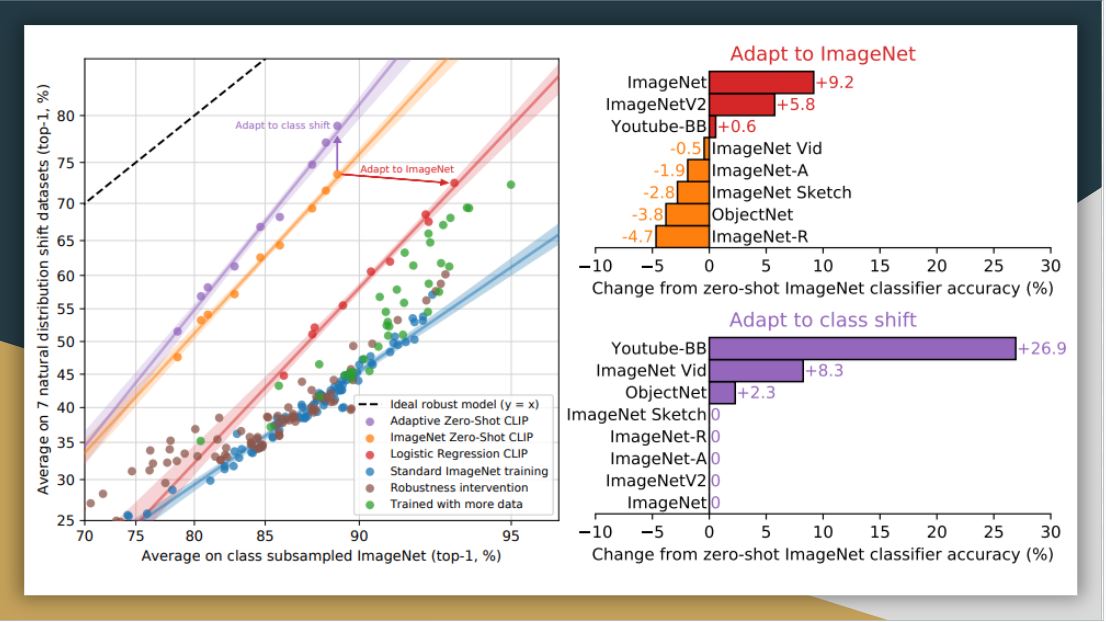 |
Here, they customize zero-shot CLIP to each dataset (adapt to class shift in purple) based on class names. While this supervised adaptation to class shift increases ImageNet accuracy by around 10 percent, it slightly reduces the average robustness. From the right side, the improvements are concentrated on only a few datasets.
On the other hand, when they adapt CLIP to fully supervised logistic regression classifiers on the best CLIP model’s features, it comes close to the standard ImageNet training in terms of robustness. Thus, it seems that the representation itself in zero-shot CLIP has more value with more stability and nuance.
 |
There are various works following CLIP based on this contrastive learning structure. The first extension is to further scale up texts and images. The second is to design better models.
Reproducible Scaling Laws
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. CVPR 2023. PDF
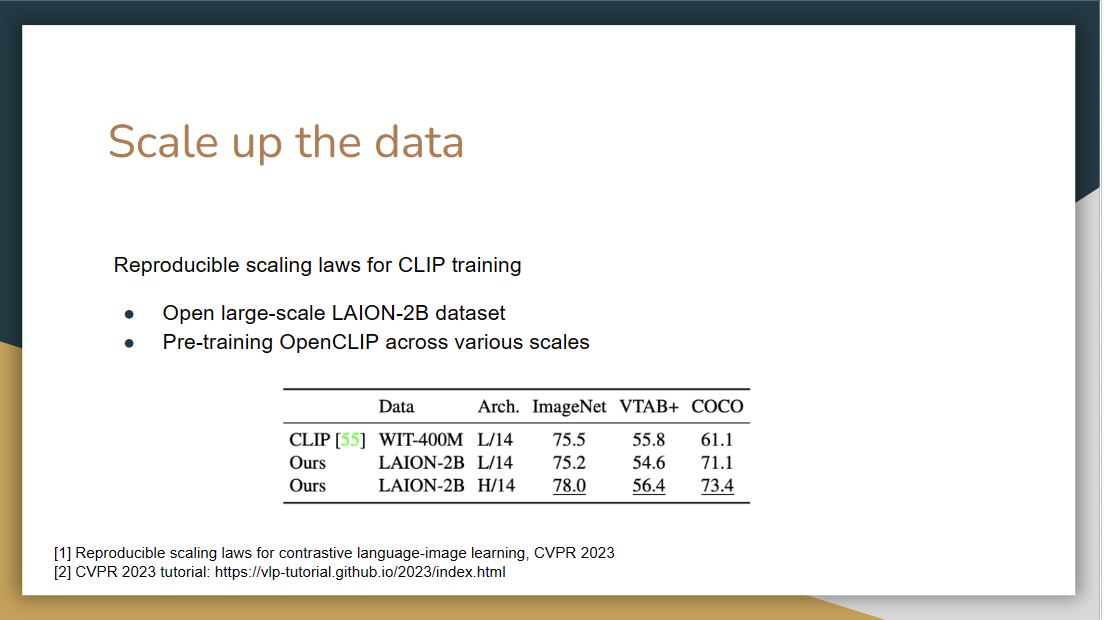 |
This paper used the open larges scale LAION-2B dataset to pre-train OpenCLIP across different scales.
Datacomp
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt. DataComp: In search of the next generation of multimodal datasets. arxiv 2023. PDF
 |
This paper talked about how should we scale data? Should we scale it up with noisier and noisier data?
Their focus is to search the next-generation image-text datasets. Instead of fixing the dataset and designing different algorithms, the authors propose to fix the CLIP training method but vary the datasets instead. With this method, they come up with a high-quality large-scale dataset.
FILIP
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, Chunjing Xu. FILIP: Fine-grained Interactive Language-Image Pre-Training. ICLR 2022. PDF
 |
FILIP scales CLIP training via masking. It randomly masks out image patches with a high masking ratio, and only encodes the visible patches. It turns out this method does not hurt performance but improves training efficiency
K-Lite
Sheng Shen, Chunyuan Li, Xiaowei Hu, Jianwei Yang, Yujia Xie, Pengchuan Zhang, Zhe Gan, Lijuan Wang, Lu Yuan, Ce Liu, Kurt Keutzer, Trevor Darrell, Anna Rohrbach, Jianfeng Gao. K-LITE: Learning Transferable Visual Models with External Knowledge. NeurIPS 2022. PDF
 |
Another line of work focuses on improving the language side model design of CLIP. The model K-Lite utilizes the Wiki definition of entities together with the original alt-text for contrastive pre-training. Such knowledge is useful for a variety of domains and datasets, making it possible to build a generic approach for task-level transfer.
 |
Recall that in the motivating example, we argue that more modalities will enhance the learning process.
ImageBind
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, Ishan Misra. ImageBind: One Embedding Space To Bind Them All. arxiv 2023. PDF
 |
Imagebind tries to use more modalities to improve performance. However, one challenge here is that not all generated data are naturally aligned due to the lack of a corresponding relationship in the training set.
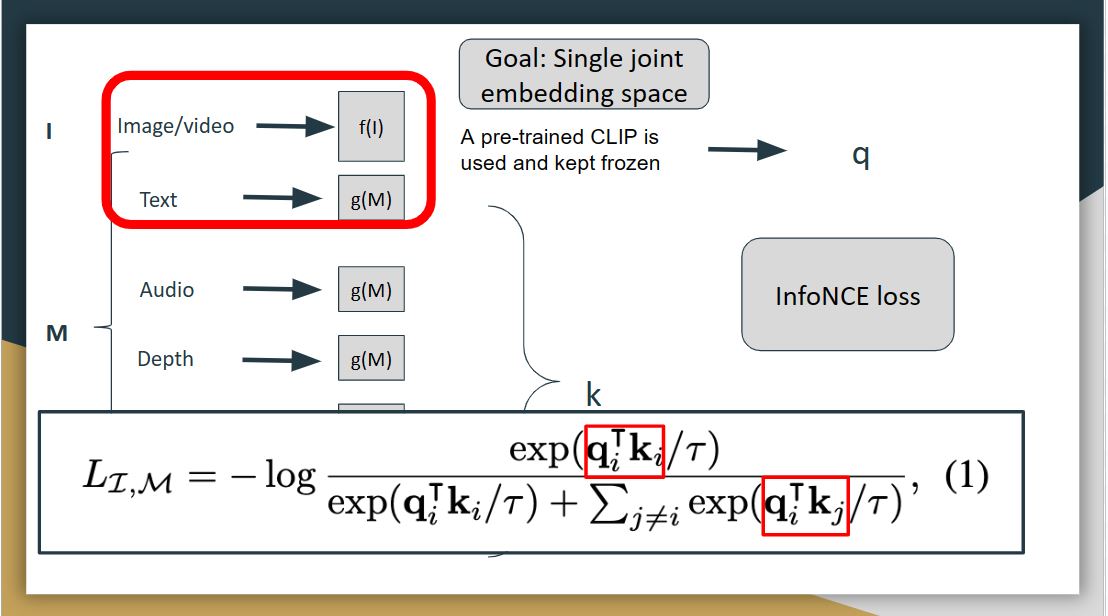 |
For ImageBind, there are different modalities include image, text, video, audio, depth, thermal, and IMU, which contains the accelerator, and gyroscope data. The goal of ImageBind is to learn a single joint embedding space for all the modalities, and then use image as the binding modality. Here I denotes image modality, and M denotes all the other modalities. They use deep neural networks as encoders to extract embeddings from each of the modalities, so each modality has it own encoder, just like CLIP.
During the training, the image and text modality was kept frozen, and the weights of other modalities were updated, and this freezing shows the alignment to emerge between other modalities for which we don’t have any natural alignment, for example, between audio, and depth.
The preprocessed inputs are passed through encoders and then passed through a simple linear layer to make sure they are of same dimension before being trained with the loss called infoNCE loss. This loss is a modified cross-entropy loss, which extends the contrastive learning to multiple modalities. Let the output for image be q, and the output for other modalities be k. The loss here tries to align image modality with all other modalities.
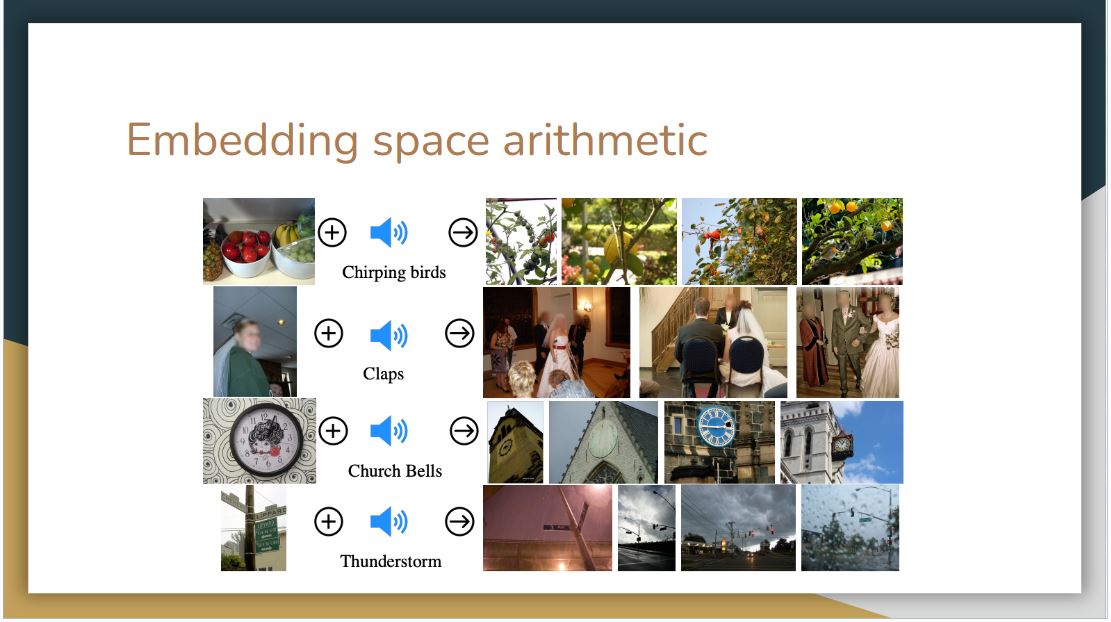 |
They study whether ImageBind’s embeddings can be used to compose information across modalities. The above figure shows image retrievals obtained by adding together image and audio embeddings. The joint embedding space allows for us to compose two embeddings: e.g., image of fruits on a table + sound of chirping birds and retrieve an image that contains both these concepts, i.e., fruits on trees with birds. Such emergent compositionality whereby semantic content from different modalities can be composed will likely enable a rich variety of compositional tasks.
 |
By utilizing the audio embedding of ImageBind, it is possible to design an audio-based detector that can detect and segment objects based on audio prompts.
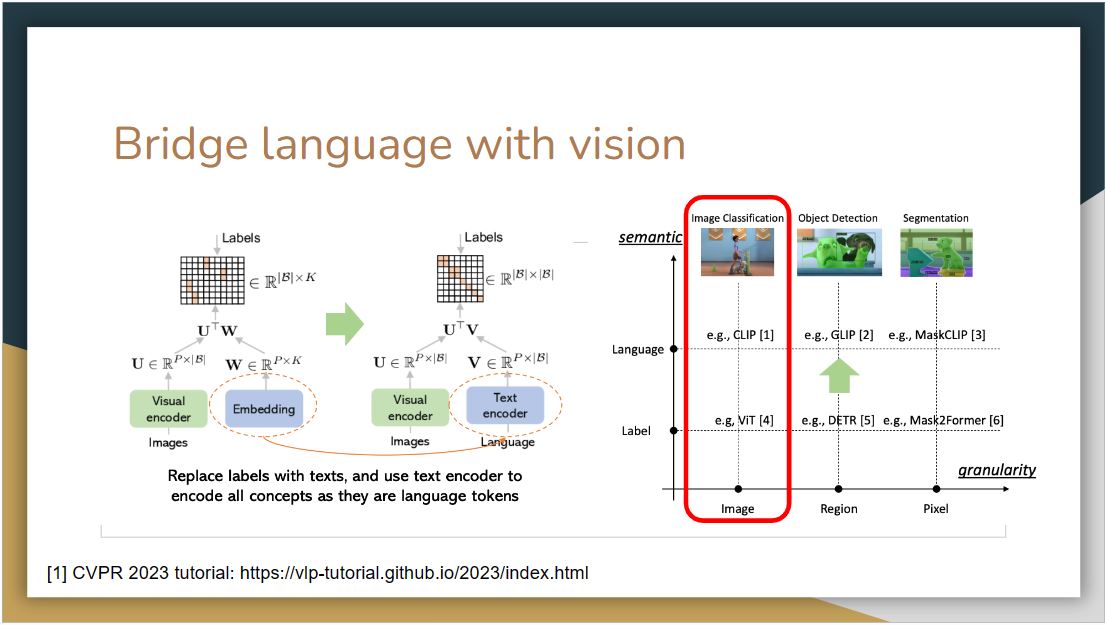 |
As proposed in CLIP, replacing labels with textual descriptions and using a text encoder to encode them can feasibly convert closed-set problems to open-set ones. A number of works have been proposed to transform different computer vision tasks by replacing the label space with language space.
 |
For the first question, we believe there are several differences between humans and machines for cognition. Although these models will outperform humans on several specific tasks, they also have limitations. For example, humans will perceive an image as a whole, but machines perceive it pixel by pixel. This ensures humans are good at using context to interpret images and text. While these models can recognize patterns and correlations between words and images, they may not fully grasp the broader context as humans do.
For the second question, the presenter gave an example that there is a specific food in Wuhan called “hot dry noodles”. When we give a picture of this kind of noodles with the caption “hot dry noodles in Wuhan”, the multi-mode models will output how this food is popular in Wuhan. However, if we replace the caption as “hot dry noodles in Shandong”, the model will still describe this noodles in Wuhan instead of Shandong. The presenter believes this is an example of bias because a lot of data on this noodles is associated with Wuhan. Thus, even though the caption of the image is changed, the model can not comprehend because the representation is fixed.
Readings and Discussion Questions
Monday 27 November: Transferring and Binding Multi-Modal Capabilities:
Readings for Monday:
Required: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. PMLR 2021. PDFOptional: OpenAI. CLIP: Connecting text and images. Blog 2021.Required: Sandhini Agarwal, Gretchen Krueger, Jack Clark, Alec Radford, Jong Wook Kim, Miles Brundage. Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications. PDFRequired: Meta AI. ImageBind: Holistic AI Learning Across Six Modalities. Blog 2023.Optional: Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev, Alwala Armand, Joulin Ishan Misra. ImageBind: One Embedding Space To Bind Them All. arXiv 2023. PDFOptional: Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, Jianfeng Gao. Multimodal Foundation Models: From Specialists to General-Purpose Assistants. arXiv 2023. PDF Chapter 1-2, p5 - p25.Optional: Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, Philip Torr. A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models. arXiv 2023. PDFOptional: Anastasiya Belyaeva, Justin Cosentino, Farhad Hormozdiari, Krish Eswaran, Shravya Shetty, Greg Corrado, Andrew Carroll, Cory Y. McLean, Nicholas A. Furlotte. Multimodal LLMs for health grounded in individual-specific data. arXiv 2023. PDFOptional: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021. PDF
Questions
(Post response by Sunday, 26 November)
- What are some potential real-world applications of CLIP and ImageBind? Could these technologies transform industries like healthcare, education, or entertainment?
- How do CLIP and ImageBind mimic or differ from human cognitive processes in interpreting and linking visual and textual information?
- What are potential challenges in creating datasets for training models like CLIP and ImageBind? How can the quality of these datasets be ensured?
- What are the potential ethical implications of technologies like CLIP and ImageBind, especially in terms of privacy, bias, and misuse? How can these issues be mitigated?